

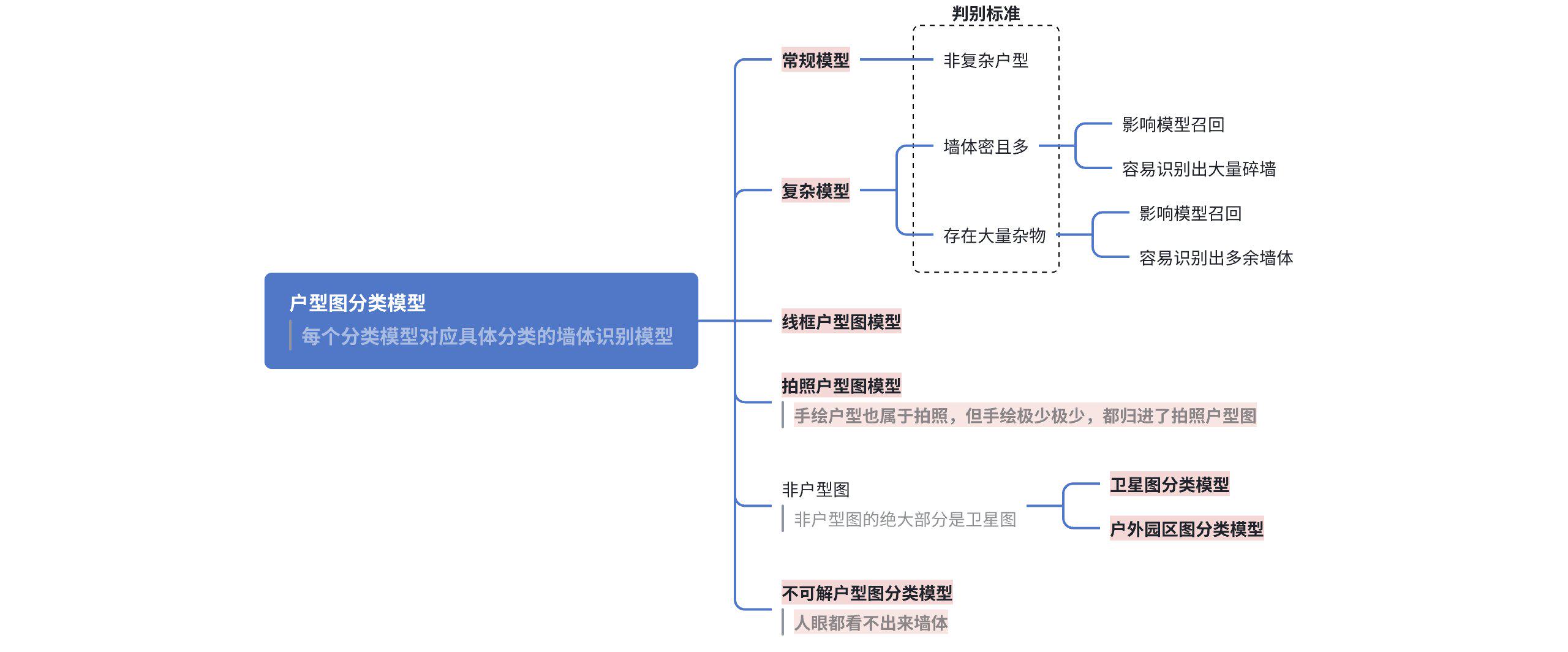
🔎V1.0 户型分类
- 多分类模型,耦合强,复杂-户外-非户型图不一定完全分开
- 多二分类模型,整体数据处理流程为漏斗型,精度最强的二分类模型前置,尽量去提升整体分类的精度
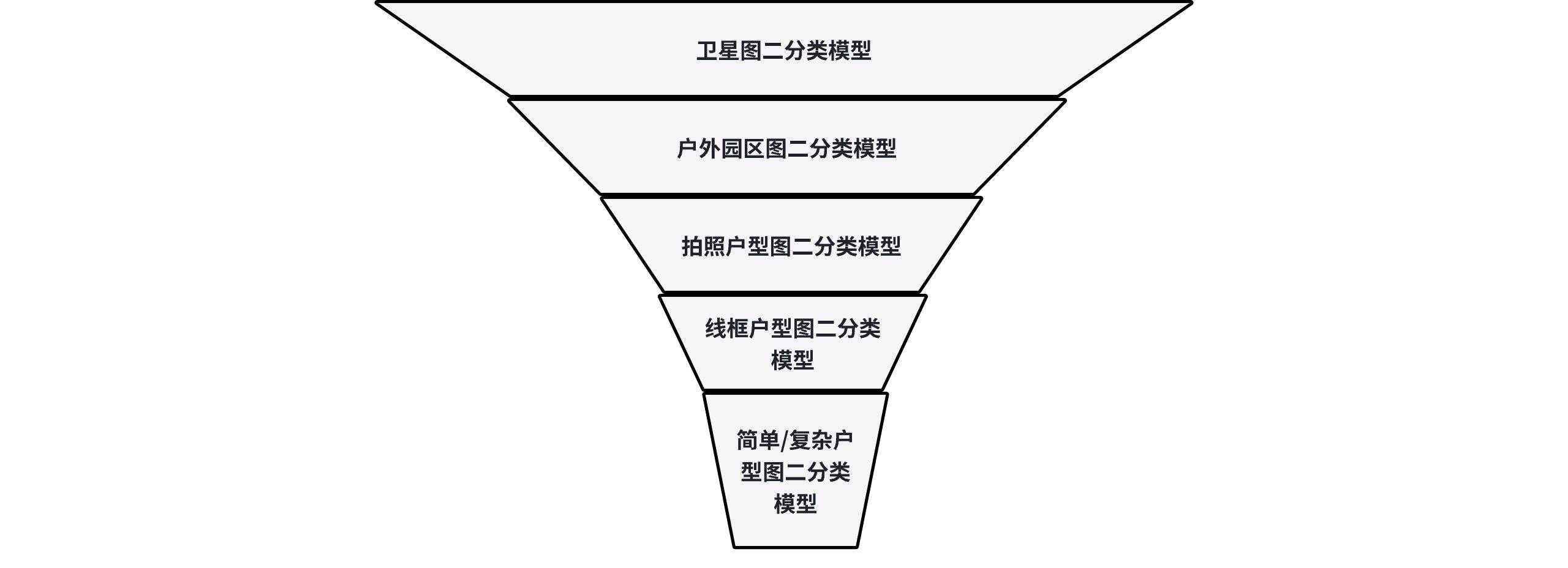
📑开发RoadMap
| 新类别 | 旧类别 | 样本下载 | 样本清洗 | 样本去重 | 样本上载 | 初次训练 | 增量训练1 | 增量训练2 | 增量训练3 | 概率分布 | 误差样本 | 验收(使用6-9月生产数据进行验证) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 线框 | 线框 | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | 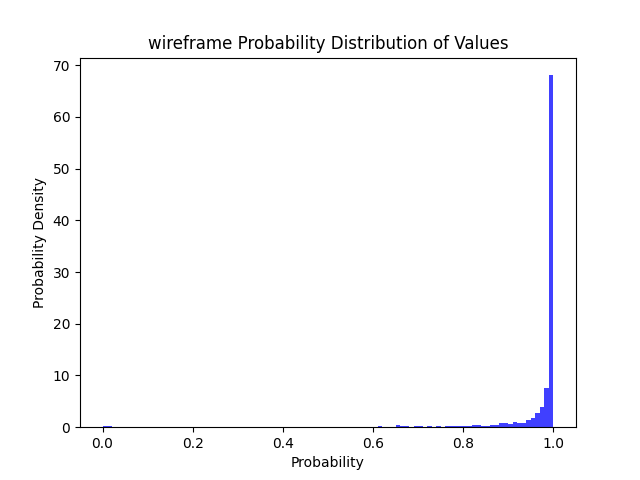 |
✔ | ✔ |
| 卫星 | 卫星 | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | 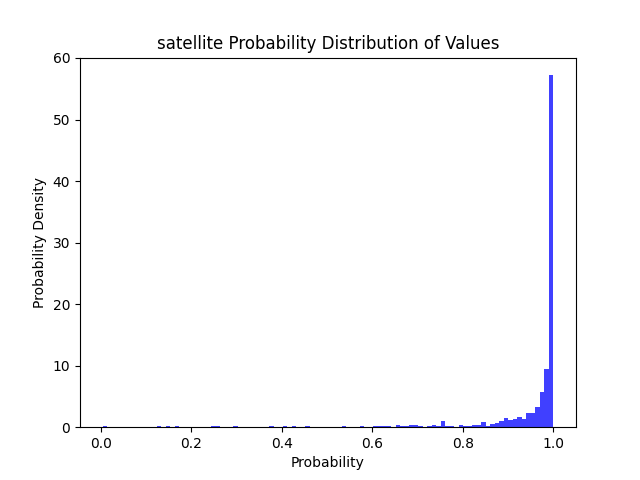 |
✔ | ✔ |
| 拍照 | 拍照 | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | 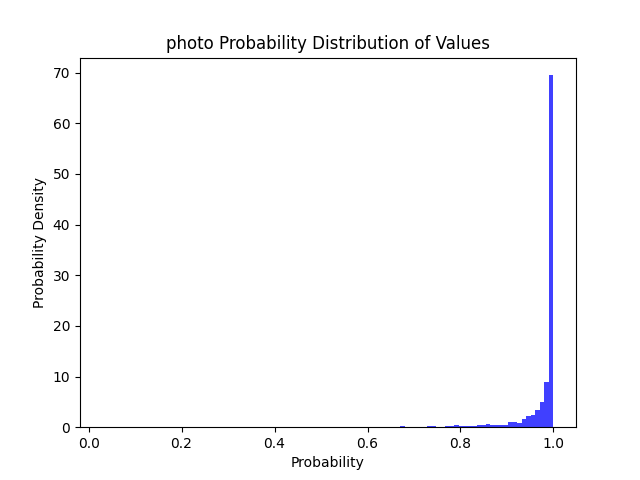 |
✔ | ✔ |
| 简单 | 全彩 | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | 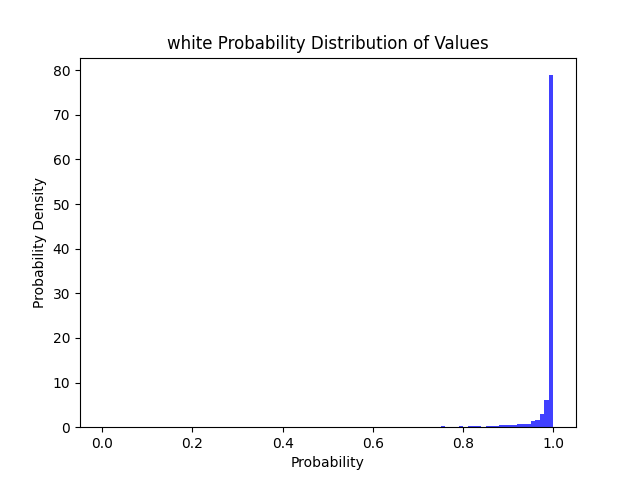 |
✔ | ✔ |
| 非全彩 | ✔ | ✔ | ✔ | ✔ | ||||||||
| 复杂 | 干扰遮挡 | ✔ | ✔ | ✔ | ✔ | |||||||
| 干扰不遮挡 | ✔ | ✔ | ✔ | ✔ | ||||||||
| 墙体小于30 | ✔ | ✔ | ✔ | ✔ | ||||||||
| 墙体大于30 | ✔ | ✔ | ✔ | ✔ | ||||||||
| 户外园林 | 不存在 | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | 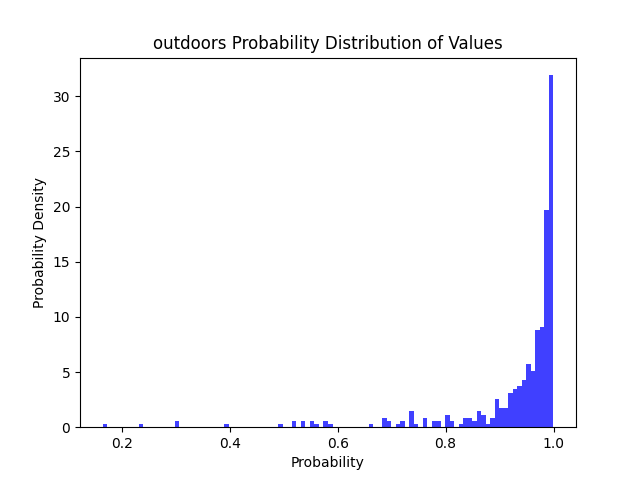 |
✔ | ✔ |
| 不可解户型 | 不存在 | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | 先暂停 | ✔ |
🔥模型性能验证
使用6-9月生产上户型图进行验证
一文记住什么是TP/TN/FP/FN?_tp fp tn fn分别代表什么-CSDN博客
| 类别 | 总样本量 TP+FP+TN+FN | 样本量 TP+FP | 错误样本 FP | 遗漏样本 FN | Accuracy | Precison | Recall |
|---|---|---|---|---|---|---|---|
| 线框 | 7333 | 270 | 17 | 6 | 0.996863 | 0.93 | 0.98 |
| 卫星 | 7333 | 122 | 3 | 1 | 0.999455 | 0.97541 | 0.991667 |
| 拍照 | 7333 | 216 | 0 | 7 | 0.999045 | 1 | 0.96861 |
| 简单 | 7333 | 5229 | 29 | 0 | 0.99 | 1 | |
| 复杂 | 7333 | 1479 | 2 | 1 | 0.999591 | 0.998648 | 0.999323 |
| 户外园林 | 7333 | 17 | 1 | 1 | 0.999727 | 0.941176 | 0.941176 |
🛠模型静态量化(Beta)
注意!!!!量化模型仅支持推理且不支持GPU加速,但经过量化的模型,CPU推理耗时可以大幅降低,但仍不至于达到GPU推理的效率
Quantization — PyTorch 2.3 documentation
(beta) Static Quantization with Eager Mode in PyTorch — PyTorch Tutorials 2.3.0+cu121 documentation
| 任务 | 模型 | 模型大小 | 耗时 | >=50 | >=80 | >=90 | >=95 | 总结 | |
|---|---|---|---|---|---|---|---|---|---|
| 线框图 | 全精度 Resnet50 | 94.35 MB | CPU: 1.13 s GPU: 0.15 s |
97% | 93% | 88% | 84% | 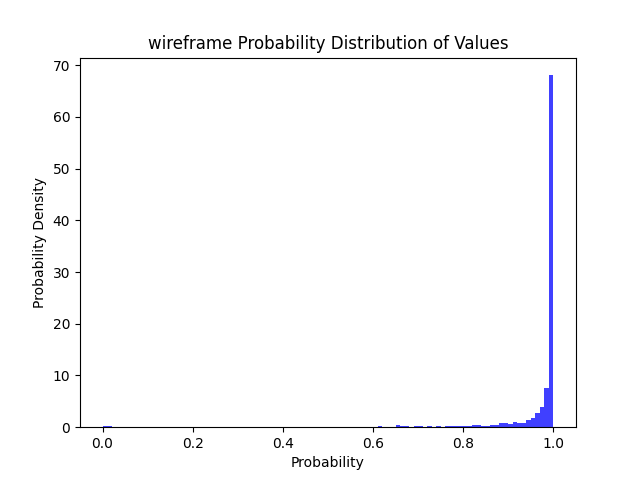 |
>=50精度下降 9% >=80精度下降 15% >=90精度下降 18% >=95精度下降 23% |
| 线框图 | INT8 Resnet50 | 23.69 MB | CPU: 0.51 s | 88% | 78% | 70% | 61% | 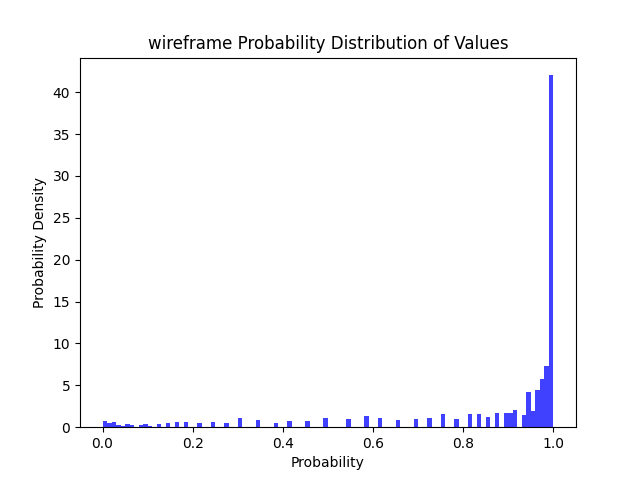 |
|
| 卫星图 | 全精度 Resnet50 | 94.35 MB | CPU: 1.21 s GPU: 0.09 s |
97% | 91% | 85% | 77% | 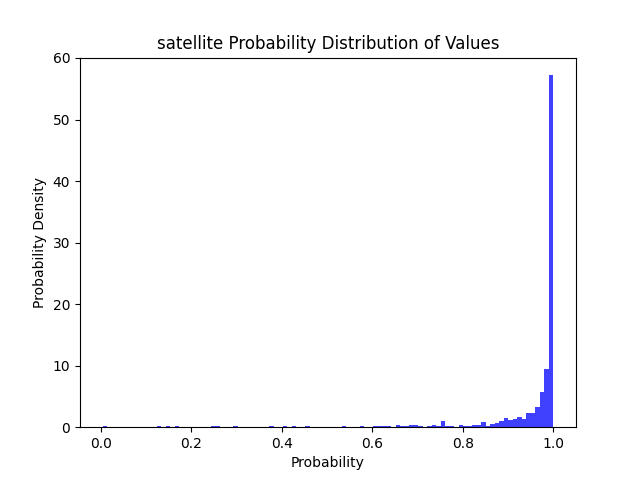 |
文件大小减少 74% 耗时降低 56% >=50精度下降 2% >=80精度下降 9% >=90精度下降 16% >=95精度下降 17% |
| 卫星图 | INT8 Resnet50 | 24.14 MB | CPU: 0.53 s | 95% | 82% | 69% | 60% | 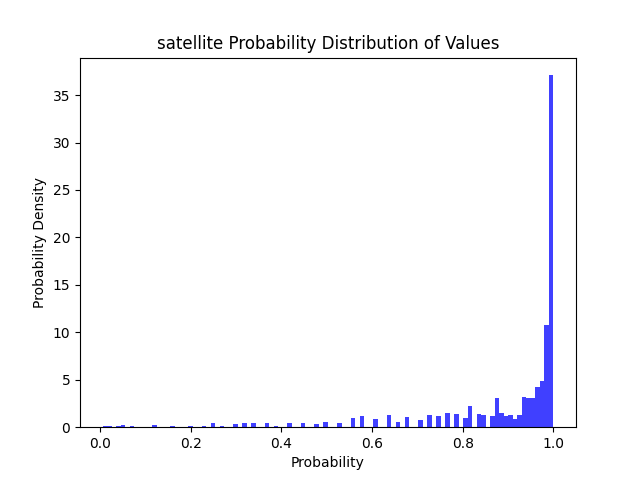 |
|
| 拍照图 | 全精度 Resnet50 | 94.35 MB | CPU: 1.12 s GPU: 0.11 s |
99% | 96% | 93% | 86% | 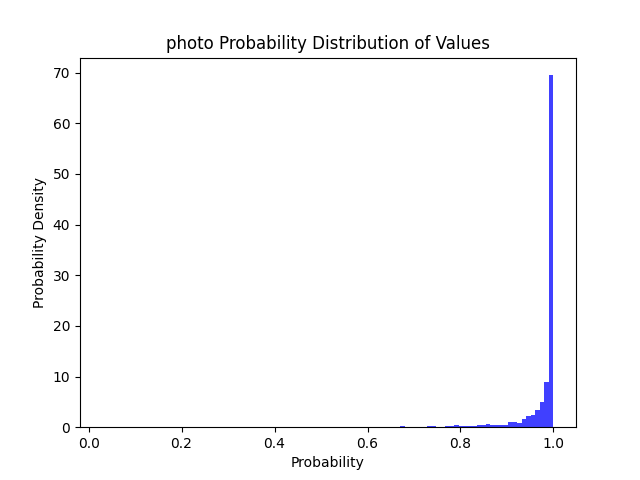 |
>=50精度下降 1% >=80精度下降 2% >=90精度下降 7% >=95精度下降 9% |
| 拍照图 | INT8 Resnet50 | 24.14 MB | CPU: 0.49 s | 98% | 94% | 86% | 76% | 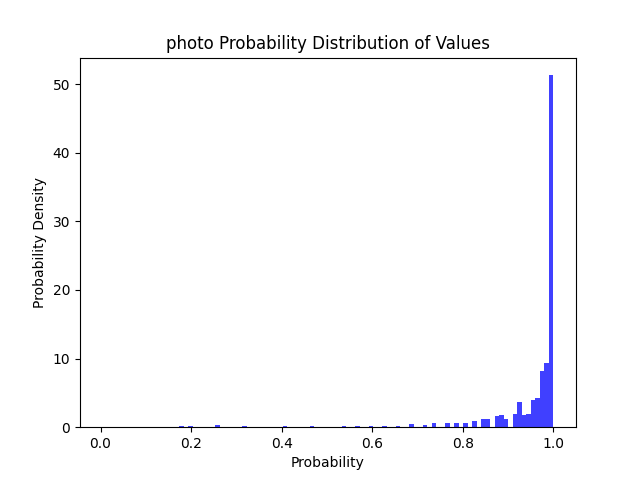 |
|
| 简单/复杂 | 全精度 Resnet50 | 94.35 MB | CPU: 1.11 s GPU: 0.15 s |
98% | 96% | 94% | 90% |  |
>=50精度下降 2% >=80精度下降 7% >=90精度下降 11% >=95精度下降 16% |
| 简单/复杂 | INT8 Resnet50 | 23.69 MB | CPU: 0.56 s | 96% | 89% | 83% | 74% | 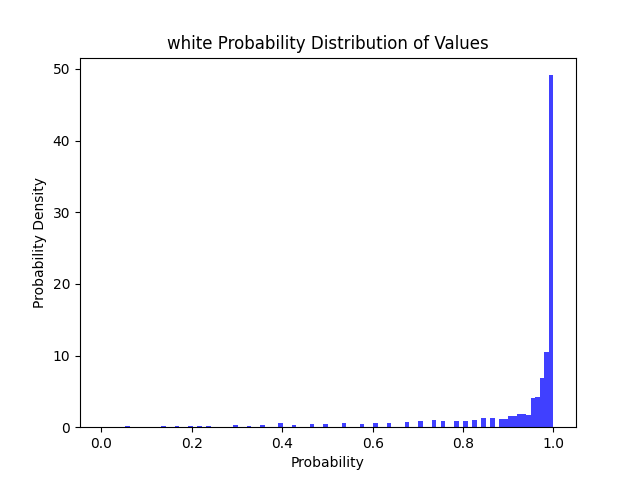 |
模型结构化剪支(Beta)
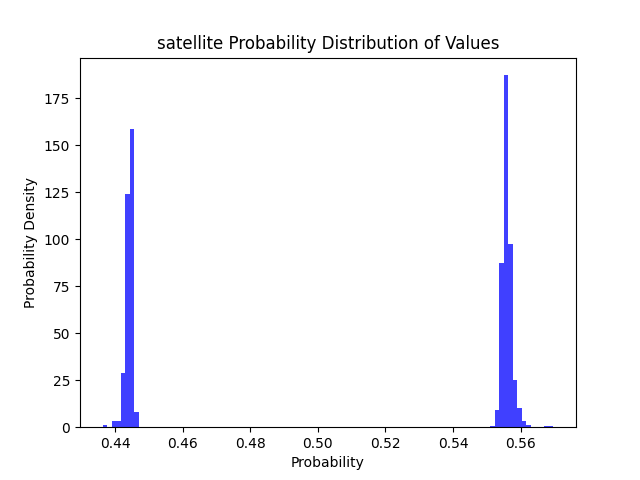
整个大活,以卫星图为例,直接裁剪掉全精度模型的90%权重,性能如下,剪完性能直接拉了,完全没有表达了:
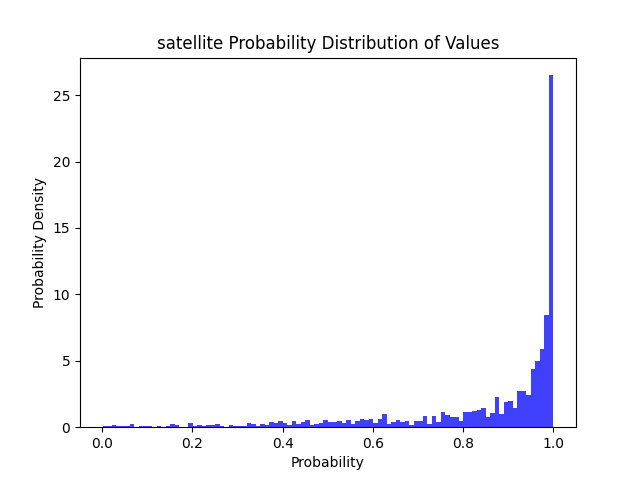
在剪支模型基础上进一步微调,性能恢复如下:
| 任务 | 模型 | 模型大小 | 显存占用 | 耗时 | >=50 | >=80 | >=90 | >=95 | 总结 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 卫星图 | 全精度 | 94.35 MB | 450.4 MB(推理+模型) 256.4 MB(模型) |
CPU: 1.21 s GPU: 0.14 s |
97% | 91% | 85% | 77% | 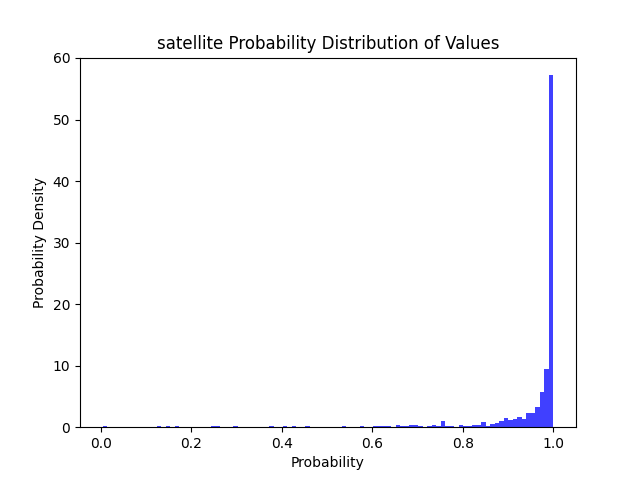 |
>=50精度下降 7% >=80精度下降 17% >=90精度下降 24% >=95精度下降 27% |
| 卫星图 | 结构化剪支 | 1.10 MB | 366.4 MB(推理+模型) 96.4 MB(模型) |
CPU: 0.22 s GPU: 0.13 s |
90% | 74% | 61% | 50% | 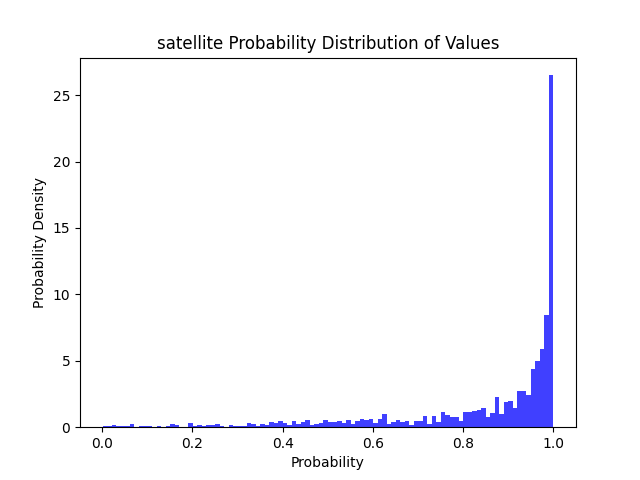 |
|
| 拍照 | 全精度 | 94.35 MB | 450.4 MB(推理+模型) 256.4 MB(模型) |
CPU: 1.31 s GPU: 0.13 s |
99% | 96% | 93% | 86% | 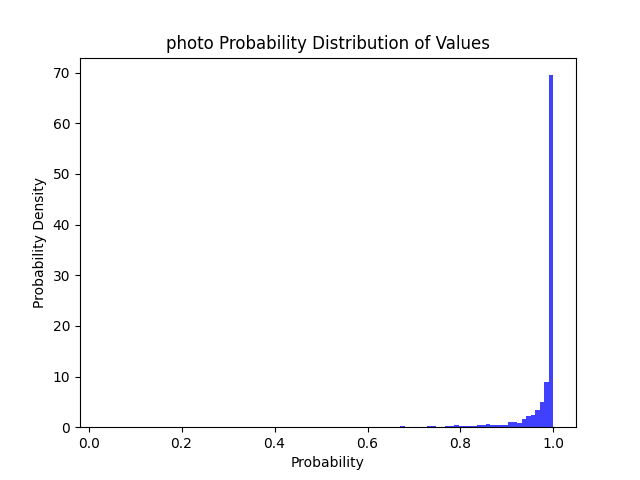 |
>=50精度下降 2% >=80精度下降 3% >=90精度下降 4% >=95精度下降 5% |
| 拍照 | 结构化剪支 | 1.10 MB | 366.4 MB(推理+模型) 96.4 MB(模型) |
CPU: 0.18 s GPU: 0.13 s |
97% | 93% | 89% | 81% | 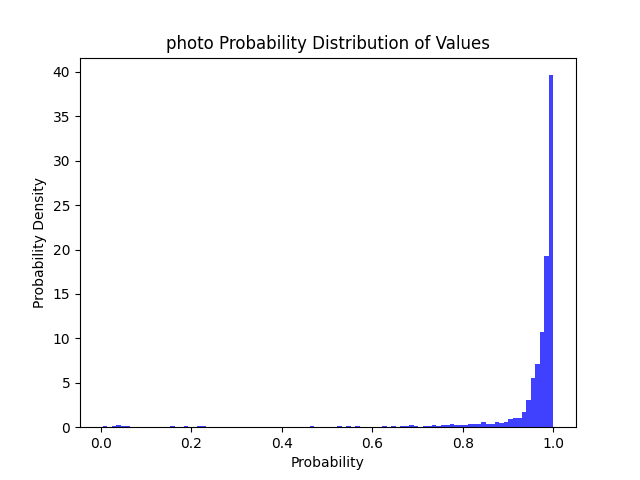 |
|
| 简单/复杂 | 全精度 | 94.35 MB | 450.4 MB(推理+模型) 256.4 MB(模型) |
CPU: 1.11 s GPU: 0.15 s |
98% | 96% | 94% | 90% | 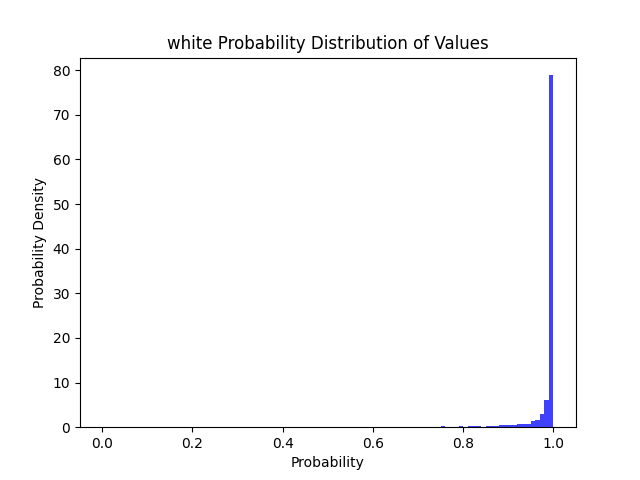 |
>=50精度下降 2% >=80精度下降 6% >=90精度下降 10% >=95精度下降 14% |
| 简单/复杂 | 结构化剪支 | 1.10 MB | 366.4 MB(推理+模型) 96.4 MB(模型) |
CPU: 0.19 s GPU: 0.12 s |
96% | 90% | 84% | 76% | 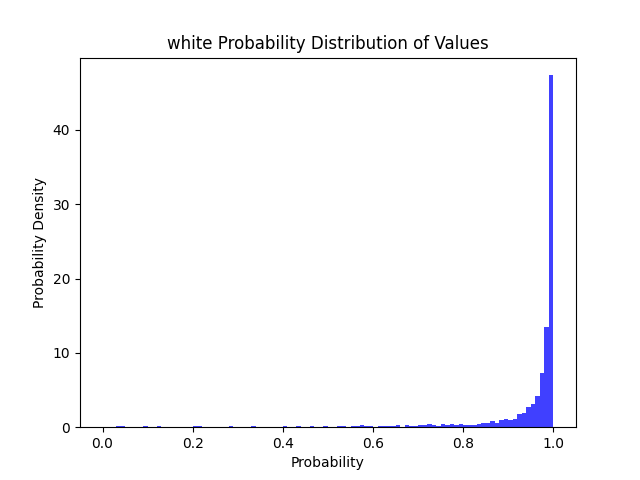 |
|
| 线框 | 全精度 | 94.35 MB | 450.4 MB(推理+模型) 256.4 MB(模型) |
CPU: 1.14 s GPU: 0.12 s |
97% | 93% | 88% | 84% | 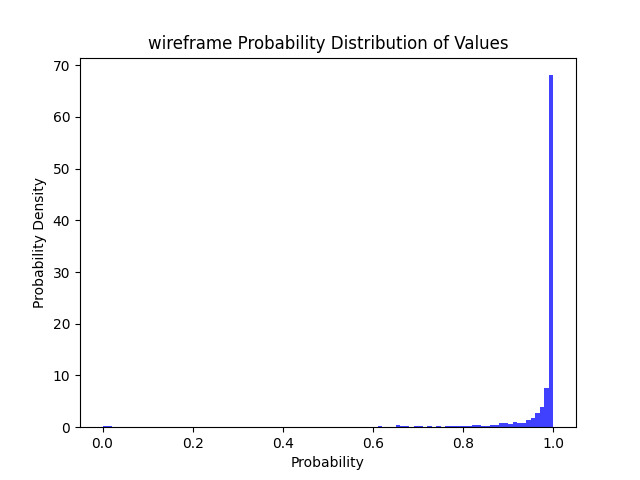 |
>=50精度下降 9% >=80精度下降 22% >=90精度下降 33% >=95精度下降 43% |
| 线框 | 结构化剪支 | 1.10 MB | 366.4 MB(推理+模型) 96.4 MB(模型) |
CPU: 0.18 s GPU: 0.14 s |
88% | 71% | 55% | 41% | 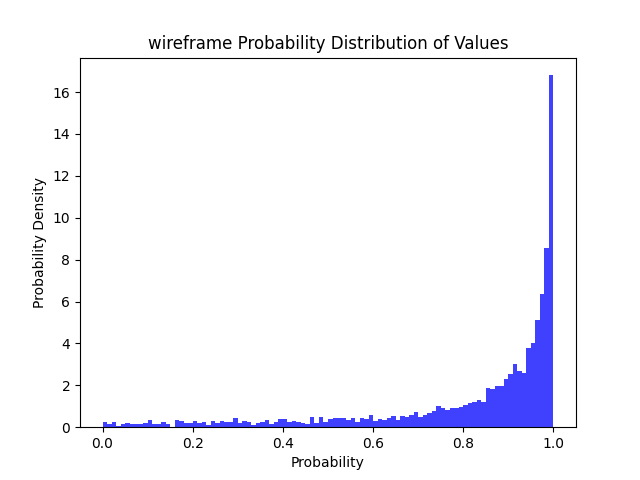 |
- CUDA推理已经很快了,剪支加速不明显,但是CPU推理加速显著
- 剪支后的模型,CPU和GPU推理耗时差距不大
- 剪支后的模型,纯CPU推理已经可以支持移动端的基线了
🐶流水线
GPU流水线,下游计算依赖上游计算 ==> 多二分类模型串行执行
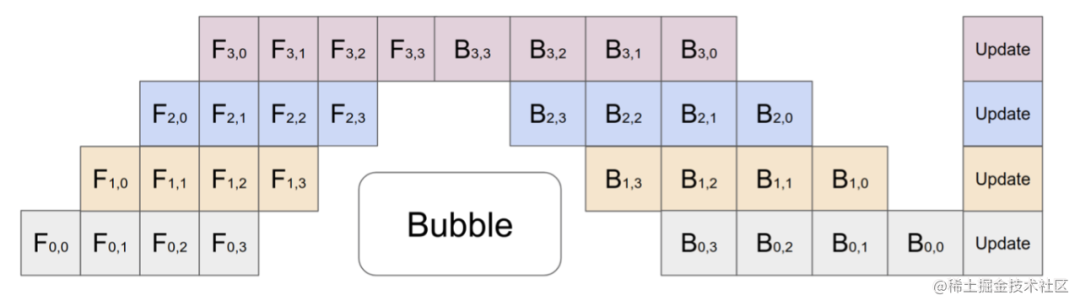
为了提升效率 ==> 并发执行多二分类模型,这导致了:
- 卫星图户型已经命中,后续其他二分类户型模型仍继续推理
- 并发模型队列为同一个队列,各个模型任务互相堵塞
优化项:
- 队列隔离,每个队列对应一个二分类模型
- 模型退场,比如卫星图户型已经命中,后续其他二分类户型模型不继续推理
原理:
并发安全的TTL缓存,模拟threadlocal,打标当前请求的模型推理结果,支撑模型退场
压测:
30并发,1w张样本进行测试
| 方案 | 显存 | 内存 | 准确率 | 耗时 |
|---|---|---|---|---|
| 单队列 | 45% | 20.3% | 6010/6413 | 14.27s |
| 队列隔离+退场 | 50% | 23.0% | 6010/6413 | 11.34s |
🐷缓存层
import hashlib
import io
from cachetools import TTLCache
# ttl: 过期时间,秒
model_cache = TTLCache(maxsize=10000, ttl=1 * 60 * 60)
def img_md5(pil_img):
with io.BytesIO() as f:
pil_img.save(f, format='PNG') # 保存 PIL 图片对象为 PNG 格式的二进制数据
image_data = f.getvalue()
md5_hash = hashlib.md5(image_data).hexdigest()
return md5_hash
def set_model_cache(md5,api_res):
model_cache[md5]=api_res
def get_model_cache(md5):
return model_cache.get(md5, None)
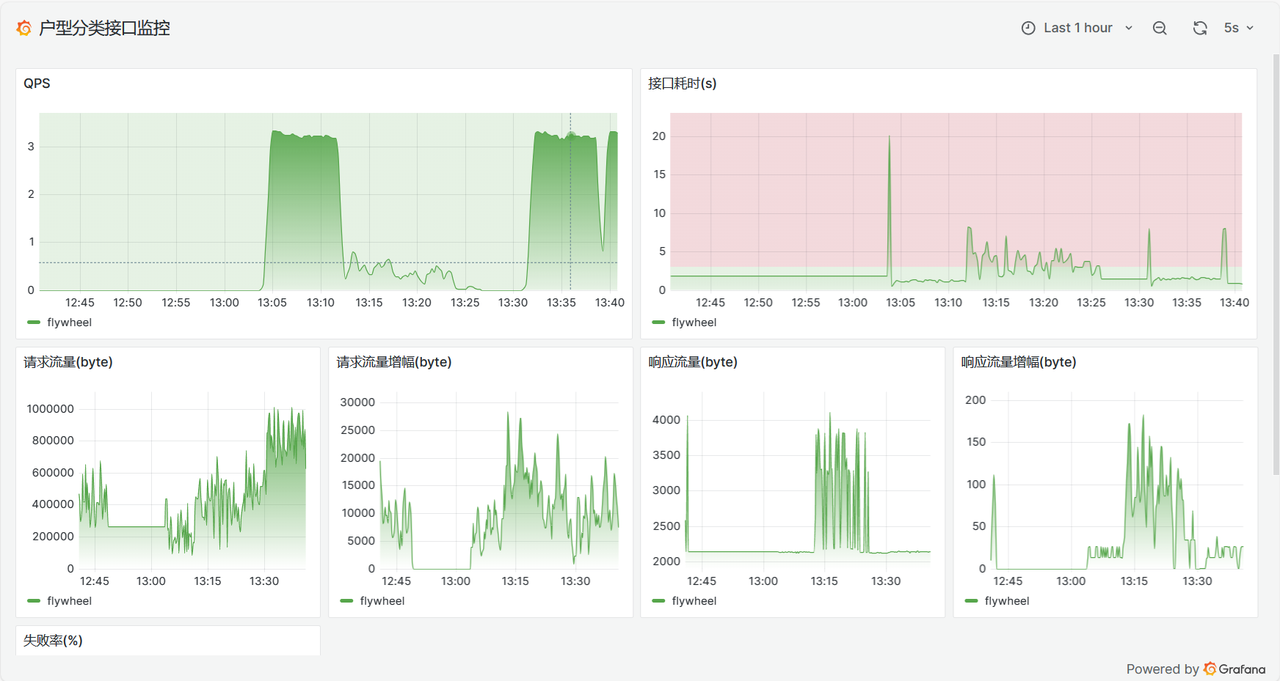
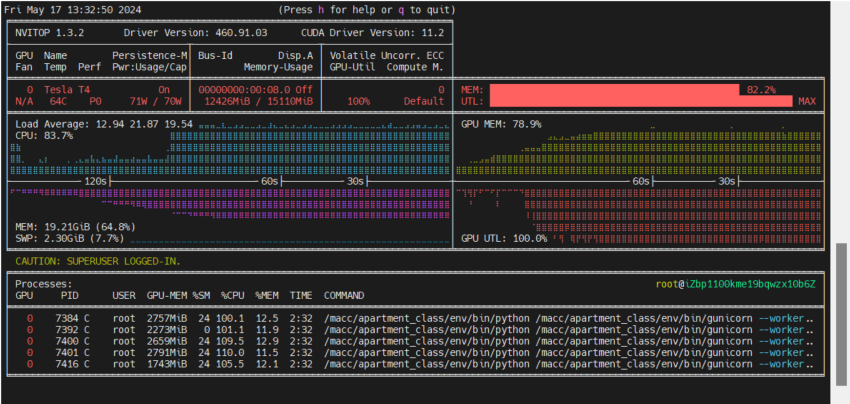
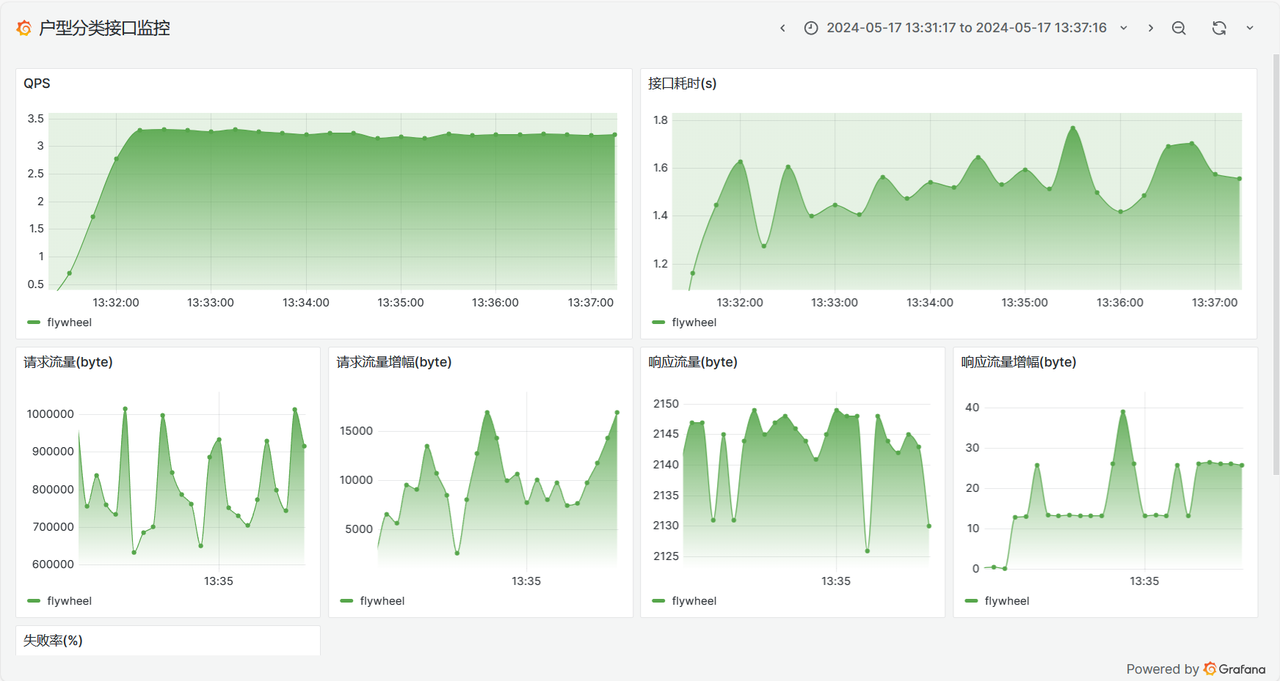
📹服务监控
📸OpenAPI
import json
import cv2
import numpy as np
from PIL import Image
import requests
API_BASE_URL = 'xxxxx'
def pred(pil_img, img_size=1024):
cv_img = cv2.cvtColor(np.array(pil_img), cv2.COLOR_RGB2BGR)
cv_img = cv2.resize(cv_img, (img_size, img_size))
_, img_encoded = cv2.imencode('.jpg', cv_img)
files = {'file': ('image.jpg', img_encoded.tobytes(), 'image/jpeg')}
body = {'task_types': 'satellite,photo,wireframe,white',}
response = requests.post(API_BASE_URL,data=body, files=files)
res = json.loads(response.content)
return res
if __name__ == '__main__':
# 替换本地的img_path
print(f'户型分类预测结果: {pred(Image.open(f"img/1.jpg"))["apartment_class"]}')
print(f'户型分类预测结果: {pred(Image.open(f"img/2.png"))["apartment_class"]}')
😡并发模型压测
日访问量太低,完全不需要太担心并发压力
- 并发度6,对应6个小二分类模型
- warm_up.lua
wrk.method = "POST"
wrk.body = ""
wrk.headers["Content-Type"] = "application/json"
thread_num=10
connection_num=10
duration='60s'
timeout='10s'
wrk -t${thread_num} -c${connection_num} -d${duration} --latency --timeout ${timeout} --script=warm_up.lua http://127.0.0.1:3872/warm_up
全精度压测结果
Running 1m test @ http://127.0.0.1:3872/warm_up
10 threads and 10 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 5.69s 837.16ms 6.35s 94.00%
Req/Sec 0.00 0.00 0.00 100.00%
Latency Distribution
50% 5.90s
75% 5.95s
90% 6.02s
99% 6.35s
100 requests in 1.00m, 63.77KB read
Requests/sec: 1.66
Transfer/sec: 1.06KB
INT8量化压测结果
Running 1m test @ http://127.0.0.1:3872/warm_up
10 threads and 10 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 13.40s 3.02s 15.77s 87.18%
Req/Sec 0.00 0.00 0.00 100.00%
Latency Distribution
50% 14.59s
75% 15.07s
90% 15.16s
99% 15.77s
39 requests in 1.00m, 22.27KB read
Requests/sec: 0.65
Transfer/sec: 379.38B
WSGI全精度压测结果
不用wrk是因为接口请求要塞图片,比较麻烦,我自己起了脚本去调30并发的接口请求
30并发
- 不建议一个进程内太多线程,争抢,本质上这个接口是计算密集服务,不是IO密集服务
- 太多线程,会导致大量Tensor放置在显存中!且内存也会大量占用
base='/macc/apartment_class'
cd $base
rm -rf $base/log.txt
rm -rf $base/error_log.txt
ps -aux | grep apartment_class_main:app | awk '{print $2}' | xargs kill -9
# 由于GIL锁存在,本质上模型服务的最大并发 = 进程数
# 单个进程中,一个时间片下,预测代码(model(input))的运行当且仅当只有一个线程可执行
# 即显存占用 = (torch占用 + [model占用 + Tensor占用]) * 进程数
# 其中,model占用、Tensor占用可以显式进行卸载
worker_num=4
thread_num=1
port=3872
echo '=============== 进程数 $worker_num ==============='
echo '=============== 线程数 $thread_num ==============='
echo '=============== 监听端口 $port ==============='
$base/env/bin/gunicorn --workers=${worker_num} --threads=${thread_num} --daemon --access-logfile=$base/log.txt --error-logfile=$base/error_log.txt -b=0.0.0.0:$port apartment_class_main:app
3进程1线程
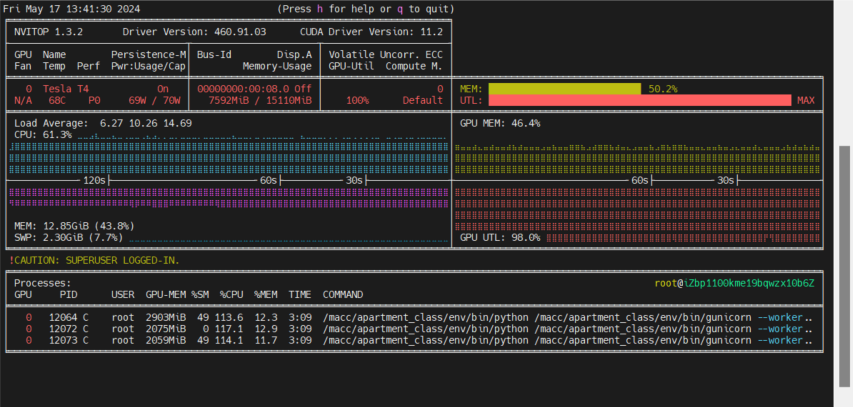
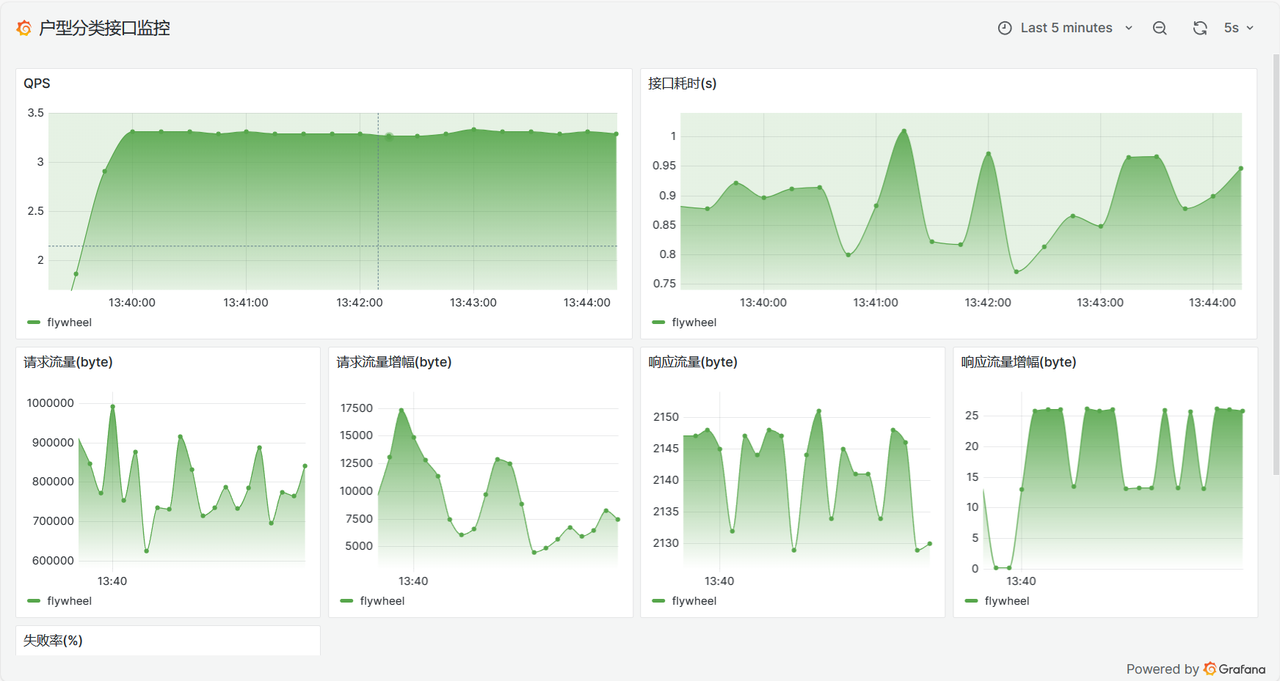
4进程1线程
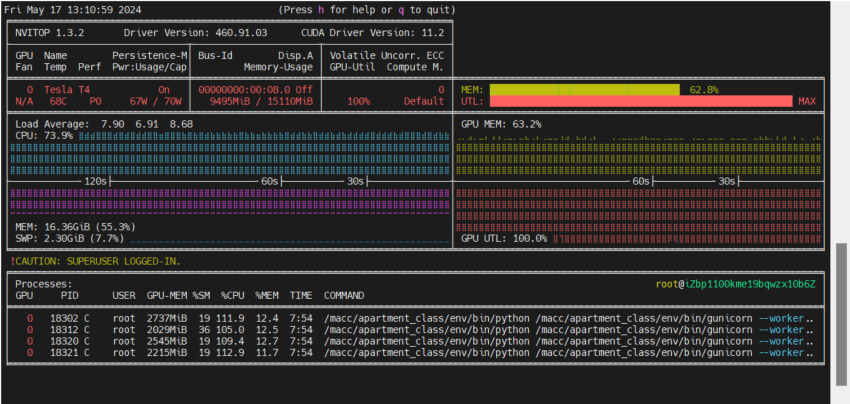
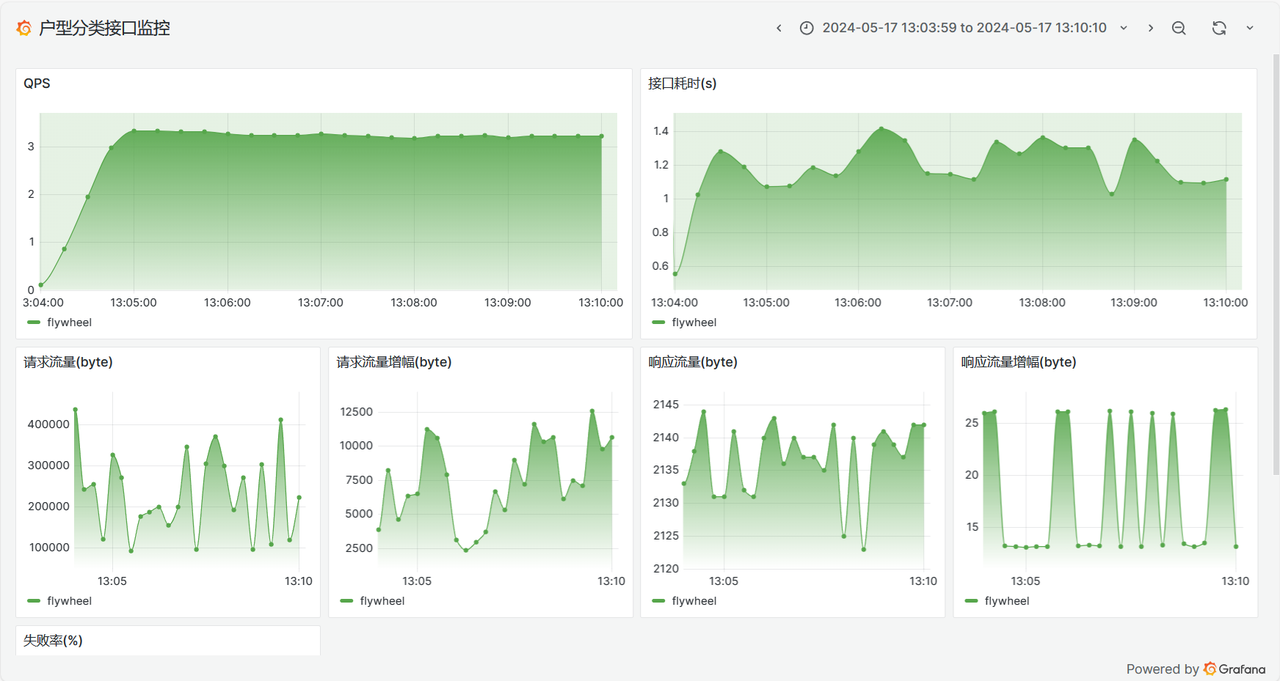
5进程1线程
评论区