


前言
制造厂商需要抽样检测流水线上生产的产品,数据公司同样也需要对自己的数据产品质量进行把控。检测的目的无非是及时发现产品或数据中的异常,从而修正偏差改善产品质量。
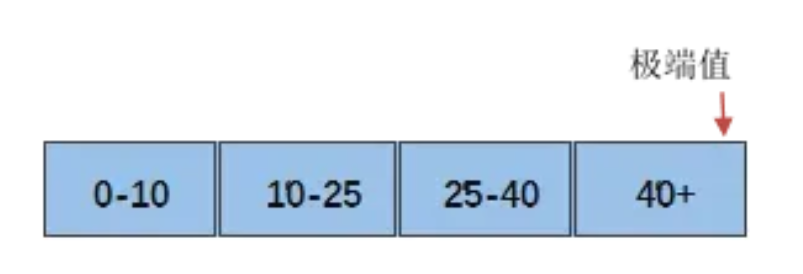
异常值在不同文献中有其不同的定义,通俗的说就是那些与其他观测值有显著偏差的观测点,有时也会称作是极端值、离群点或孤立点等,这些名词在数学的细分领域都有其不同的定义,这里不做区分。
异常值产生的原因主要是数据生成机制的不同,异常值本身不是一个贬义词,异常观测也会涵盖有用的信息,帮助分析师理解数据的分布,保证线上流程的稳健性。
一、应用场景
异常检测与监控的应用场景多样,主要包括以下:
1、**ELT流程中的数据异常。**ETL工程师在上层数据汇总过程中通常会考虑标记数据的极端值,比如单个用户的日pv数过千过万或单个用户周订单过百过千等,这将有助于数据分析师获取数据异常的先验信息。
2、**特征工程中的数据异常。**分箱操作是特征工程中常用的一种异常处理方式,在线性模型中,将变量分箱离散化可将极端值圈定在某一固定的组别,不仅能消除极端值对模型鲁棒性的影响,也能在线性性基础上引入非线性性。
3、**AB测试中的数据异常。**在计算转化率(随机变量服从0/1分布)时,个别的异常值不会影响AB测试的整体效果,但在计算人均订单数和人均pv数时,个别的极端值会对均值产生显著影响。
4、**时序数据的监控。**监控数据在时间维度上的异常情况,这里需要考虑时序数据的特性,比如趋势和周期等。
5、**欺诈检测。**金融场景中的欺诈案例也属于异常数据,机器学习中有很多优秀的算法可用来支持欺诈检测。
6、其他场景中的异常检测和监控不一一列举。
二、检测方法
1、概率统计模型
概率给出总体的分布来推断样本性质,统计则从样本出发来验证总体分布的假设。所以概率统计模型需要我们去验证模型假设的正确性,比如概率分布是否正确,参数的设置是否合理。
2、机器学习方法
机器学习无外乎监督、非监督以及半监督学习方法等,比如常见的聚类,二分,回归。此类方法往往注重模型的泛化能力,而弱化概率统计中的假设检验。历史数据的异常如果已标注,那么二分类方法是适用的,但业务数据的异常大多没有显示的人工标注,无法应用监督学习。
3、业务经验,逻辑规则
业务经验的丰富以及对数据的敏感性能更加直接地帮助理解异常数据,在一些轻量级的任务中,配置简单的逻辑规则也能达到很好的检测效果。
4、判定规则
异常值的判定规则主要采用以下两种方式:
a)区间判定
给出一个阈值区间,实际观测落在区间之外则判定为异常。例如,在时间序列和回归分析中,预测值与真实值的残差序列便可构建这样一个区间。
b)二分判定
二分判定的前提是数据包含人工标注。异常值标注为1,正常值标注为0,通过机器学习方法给出观测为异常的概率。
三、实际应用
1、从3 Sigma准则说起
借助正态分布的优良性质,3σ准则常用来判定数据是否异常。由于正态分布关于均值μ对称,数值分布在(μ-σ,μ+σ)中的概率为0.6827,数值分布在(μ-3σ,μ+3σ)中的概率为0.9973。也就是说只有0.3%的数据会落在均值的±3σ之外,这是一个小概率事件。为了避免极端值影响到模型整体的鲁棒性,常将其判定为异常值并从数据中剔除。
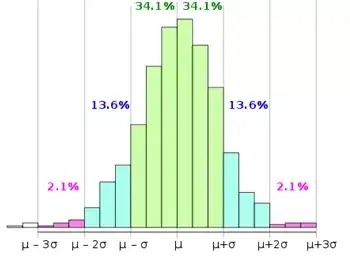
引用自: https://en.wikipedia.org/wiki/68%E2%80%9395%E2%80%9399.7_rule
正态分布的参数μ和σ极易受到个别异常值的影响,从而影响判定的有效性,因此又产生了Tukey箱型图法。
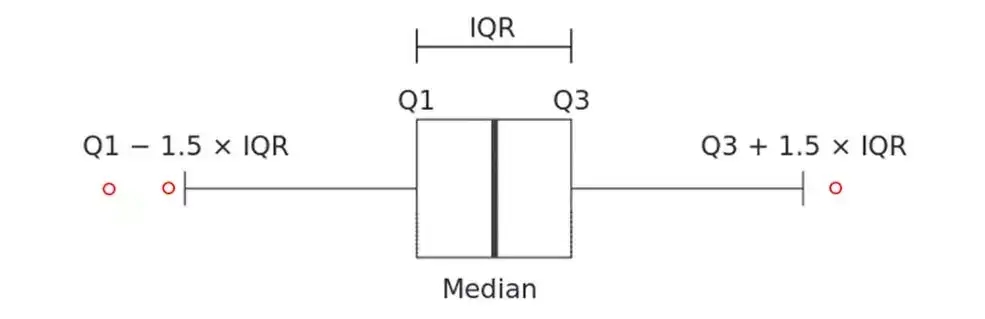
上图中IQR,即四分位间距Q3-Q1,(Q1, Q3)涵盖了数据分布最中间的50%的数据,具有稳健性。数据落在 (Q1-1.5*IQR, Q3+1.5*IQR) 范围内,则认为是正常值,在此范围之外的即为异常值。
2、BOX-COX转化
当原始数据的分布是有偏的,不满足正态分布时,可通过BOX-COX转化,在一定程度上修正分布的偏态。转换无需先验信息,但需要搜寻最优的参数λ。
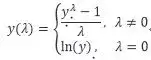
对于一个右偏数据,如下左图,λ取3.69时,转换后的数据分布近似一个正态分布,如下右图。严格地来说,在应用正态分布的性质之前,还需对转换后的数据做正态性检验。
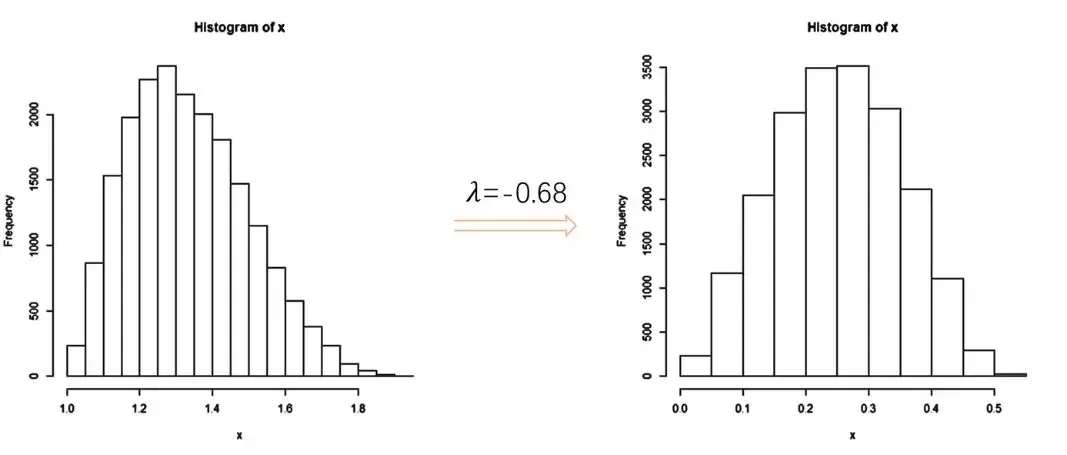
3、幂律分布vs正态分布
除了常见的正态分布,还有一种极其重要却极易被忽略的分布-幂律分布。在日常的数据分析中,订单数据和浏览数据常呈现近似幂律分布。
下图展现的是社交网络中用户数和用户粉丝数的关系,可以看出拥有200(横轴)以上的粉丝的用户数(纵轴)占极少数,而拥有<100粉丝的用户数成百上千,这就是幂律分布的特点:少数群体占有着多数的资源。
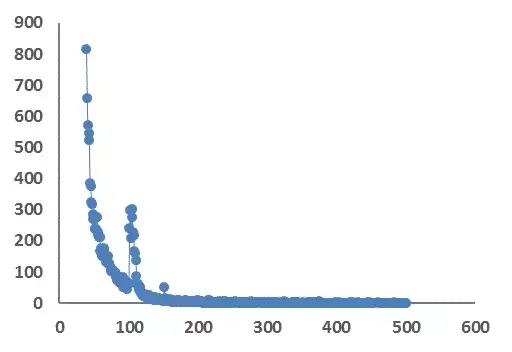
呈现幂律分布特点的数据可通过log转换使观测点近似其分布在一条直线上,方便后续分析和预测,而分布中的那些所谓的“极端值”却不能像分析正态分布那样随意的剔除。考虑到计算中数据的倾斜问题,在不影响整体效果的情况下,可根据更加细致的分位点对极端值进行取舍。
4、回归分析
在回归分析中,尤其是线性回归中,异常的数值也会对模型的拟合效果产生较大的影响。
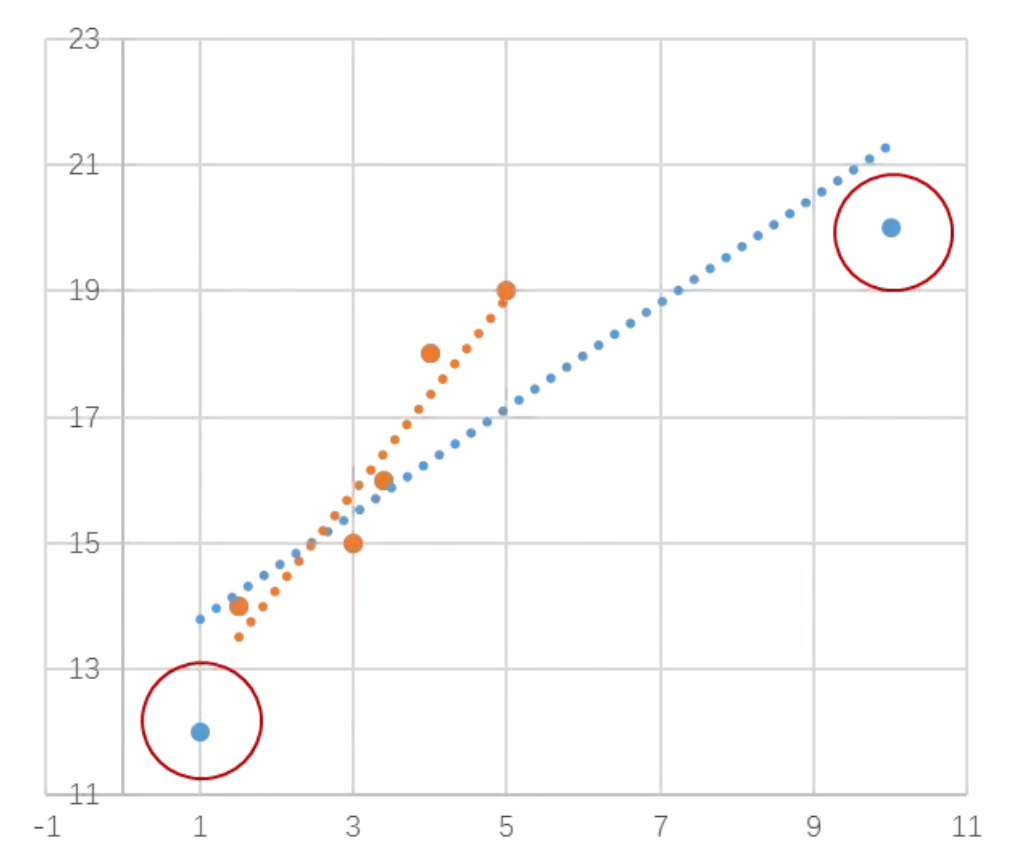
对图中7个数据点进行拟合,蓝色的回归曲线线受到右上方高杠杆值的影响,偏向了它,拟合并不理想。对高杠杆值的识别不足以用来检测回归中的异常,更有效的方式是计算每个数据点的Cook距离。
Cook距离表征了包含此观测点和剔除此观测点前后模型的拟合效果的差别,差别越大,此点对模型影响越大,可考虑删除,因为在一个稳健的模型中每个点对模型的影响都认为是均匀的。删除强影响点之后,橘色的曲线对大部分的点的拟合都比较满意。
5、基于密度的方法
在一维空间中的固有思维是较大或较小的数据会是异常,但是在高维空间中,数据是不能直接拿来比较大小的。仍以一维数据为例,考虑以下序列的异常情况:
{1,2,3,2,50,97,97,98,99}
50更有可能认为是异常或离群点,而非1或99。当数据分布的假设不是必要条件时,计算数据点的密度来判定异常也是一个行之有效的方法。
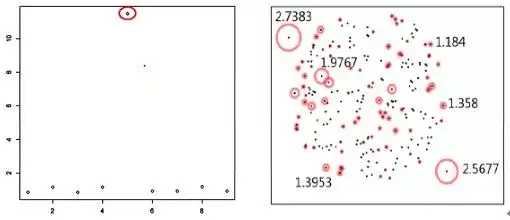
点的密度可有多种定义,但多数都会依赖距离的定义,多维空间的距离计算较为复杂,尤其当数据混入分类变量和连续数值变量的时候。以一个简单的密度方法为例,在LOF(Breunig,M., Kriegel, H., Ng, R., and Sander, J. (2000). LOF:identifying density-based local outliers.)算法中,数据的异常判定依赖于计算每个观测的局部离群因子。
离群因子表征了数据点与周围邻居点的密切程度,或者不合群的程度。因子值越大,其为异常点的可能性越大。上述一维序列的各点离群因子值如下左图,第5个点(50)对应的离群因子最高,可被判定是异常值。下右图是维基百科上一个二维空间的例子,根据局部离群因子同样可以识别出数据中的离群点。
6、业务数据的时序监控
业务数据的时序监控是对各业务线产生的时序数据,如访问量,订单量等进行异常检测,是对业务正常开展的反馈与保障。业务数据包含实时数据和离线数据,对实时性要求不高可采用T+1天监控预警。在实践中发现业务数据会有如下特点:
a)数据稀疏:有的业务数据时间跨度小,历史数据不足;有的业务数据包含缺失值,时间不连续,通常会出现在投放业务中。
b)无人工标注:历史的异常值无人工标注,后续判断异常主观性较强。
c)节假日等影响因素不可控。
常用的判定流程如下:
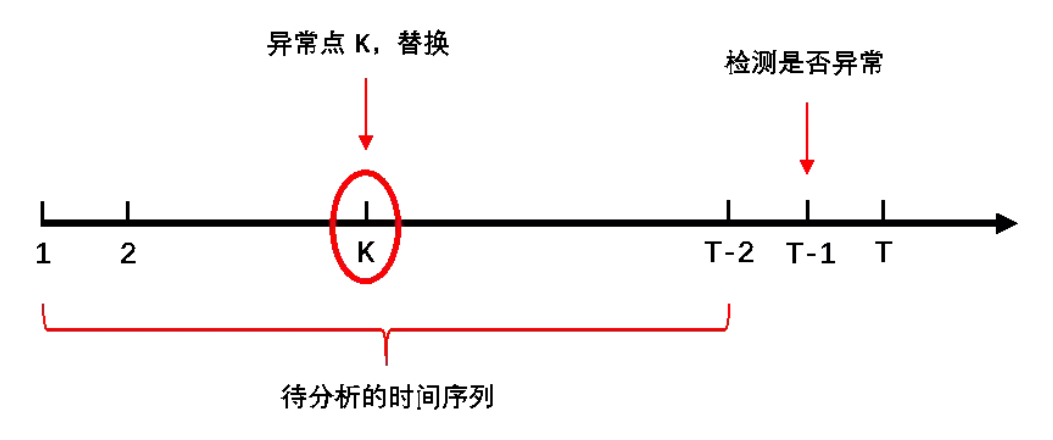
T时刻基于[1, T-2]时间段内的数据建立模型或规则来判定T-1时刻数据的是否异常。为了保证规则和模型的稳健,对于历史的异常值往往会采用平滑的方式处理。
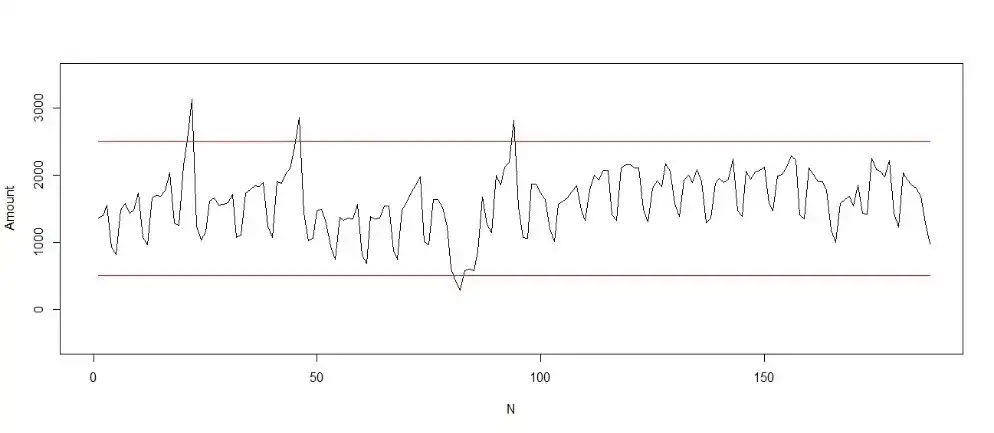
a、配置恒定阈值
数据无趋势性,近似平稳,可配置简单的恒定阈值。时刻T配置的恒定阈值是对历史数据的恒定,在T+1时刻,这个阈值会被新加入的数据更新。
b、配置动态阈值
如果时间序列含有趋势性,但无明显周期性,可以配置动态阈值。比如基于固定的移动窗口计算移动平均值和移动标准差,基于两者给出监控的上下界。动态阈值会受到移动窗口大小设定的影响,对判定当前数据异常有一定的延迟性。
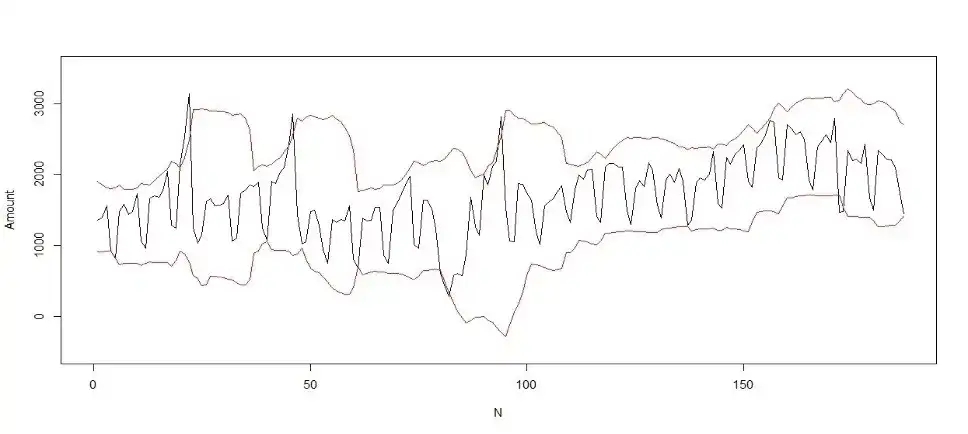
c、监控差分序列
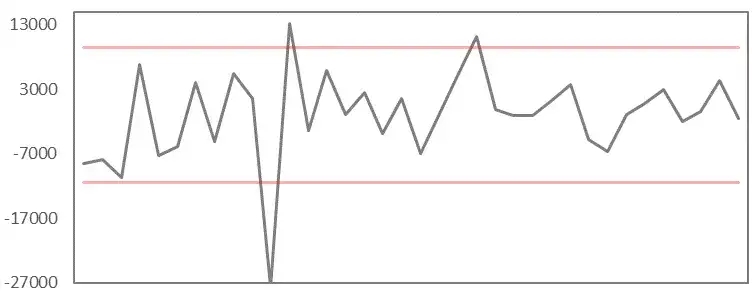
对原始序列作一阶差分,如果差分序列稳定,可对差分序列配置恒定阈值,从而判定原序列的异常情况。
原始序列:
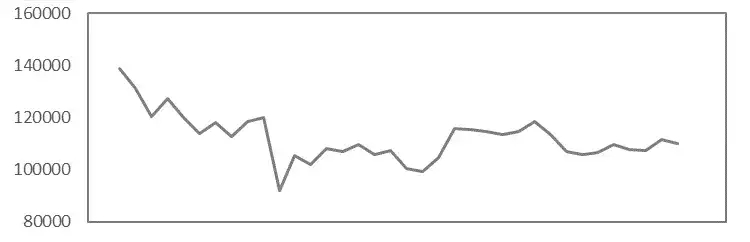
差分序列:
d、时间序列分解法
如果业务数据既有趋势性又有周期性,可将时间序列模型运用于监控任务中,如Arima,STL,TBATS等时间序列模型。在STL鲁棒加权回归时间序列分解法中,模型通过加权最小二乘回归将原始序列分解成周期序列,趋势序列和残差序列。下图从上到下依次是原始序列,周期序列,趋势序列和残差序列。
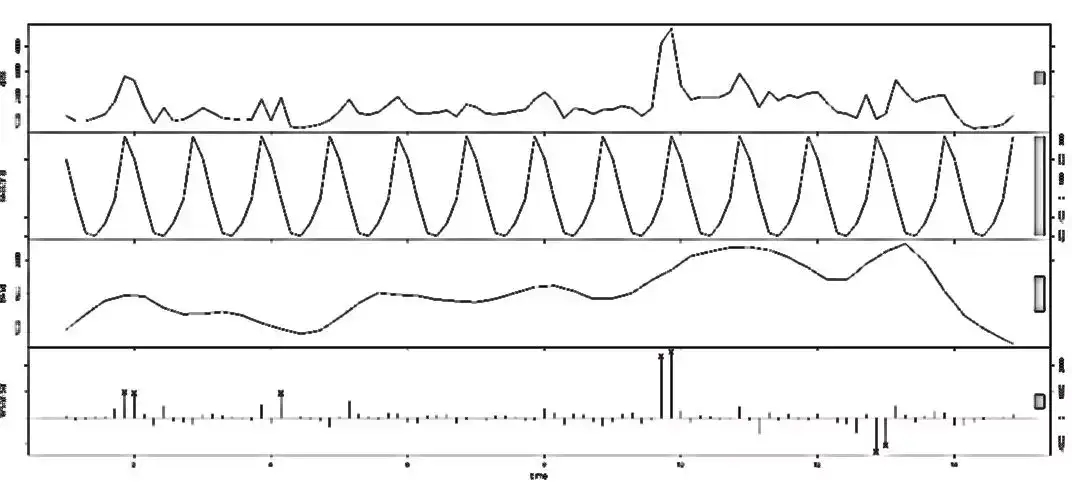
模型基于残差序列的中位数和观测的残差值赋予每个观测一个稳健权重,权重低的观测会被判定为异常。这里之所以使用残差序列的中位值,也是考虑了中位值的稳健性。
在实际应用中会发现,业务时序数据的不规则和特点的多变性往往对模型和规则提出更高的要求,不同的检测方法需要相互配合使用才能发挥作用。
四、结束语
异常检测与处理在各个领域都有其广泛的应用场景,本文仅以常见的case为例,论述了一些简单却行之有效的方法。文章并未涉及大规模数据和高维数据的异常检测,感兴趣的读者可以查阅相关文献做深入研究。
其次,在实际操作中,一种或几种检测方案也无法覆盖所有数据问题。在洞察数据分布规律的基础上,分析师需要灵活的根据数据生成机制采取合适的方法或统计模型,再辅以相应逻辑规则来顾及模型所无法触及的边边角角,让异常检测算法实际落地。
评论区