


预期目标
工单数据目前没有接入数仓的oneId,要具备关联上非埋点业务数据和数仓用户数据的能力
数据现状
虽然工单的数据目前没有必要做自然人识别,因为能构建出能用的无向图的用户,都已经加工出来他具体的账号信息了。但这并不妨碍我们基于这些数据探索自然人识别方案的探索
实现原理
构建每个用户的无向图,根据不同策略来判断两个无向图是否连通。
这边的策略主要根据业务来制定(这里大概举个例子):
- 两个无向图的手机号节点/邮箱节点可以联通,强烈建议识别为同一个人
- 两个无向图的设备指纹节点、公司节点可以联通,高度疑似识别为同一个人,可能是公司同事用同一台设备
因此,工程上的实现中,要实现如下几个功能:
- 无向图的解析,以及入库(后续有两种入库方案,基于redis和neo4j)
- 支持精确反查,依据策略(即一个/多个节点),要返回命中的无向图。如:福建省、工程商反查出所有命中的无向图
- 支持模糊反查,有时候并没有具体节点去反查。比如:我们有个策略,就是要用省份和公司类型来反查无向图,并对符合的无向图进行识别为同一个人。应返回所有省份和公司类型的可能组合,且对每个组合下对应的多个无向图进行合并
基于Redis的实现
Redis存储数据结构
| 类型 | key | value | 备注 |
|---|---|---|---|
| 无向图 | graph:09b89bfc3a6f2827890b05e1611eeb4c | json字符串 | value是解析无向图结构的json字符串 |
| 节点 | node:cmmnt_phone_number:153xxxxxxxx | [graph:xxx, graph:xxx] | value是当前该节点指向的多个无向图key |
| 节点类 | node:cmmnt_phone_number | [node:xxx, node:xxx] | value是当前该类节点指向的多个节点key |
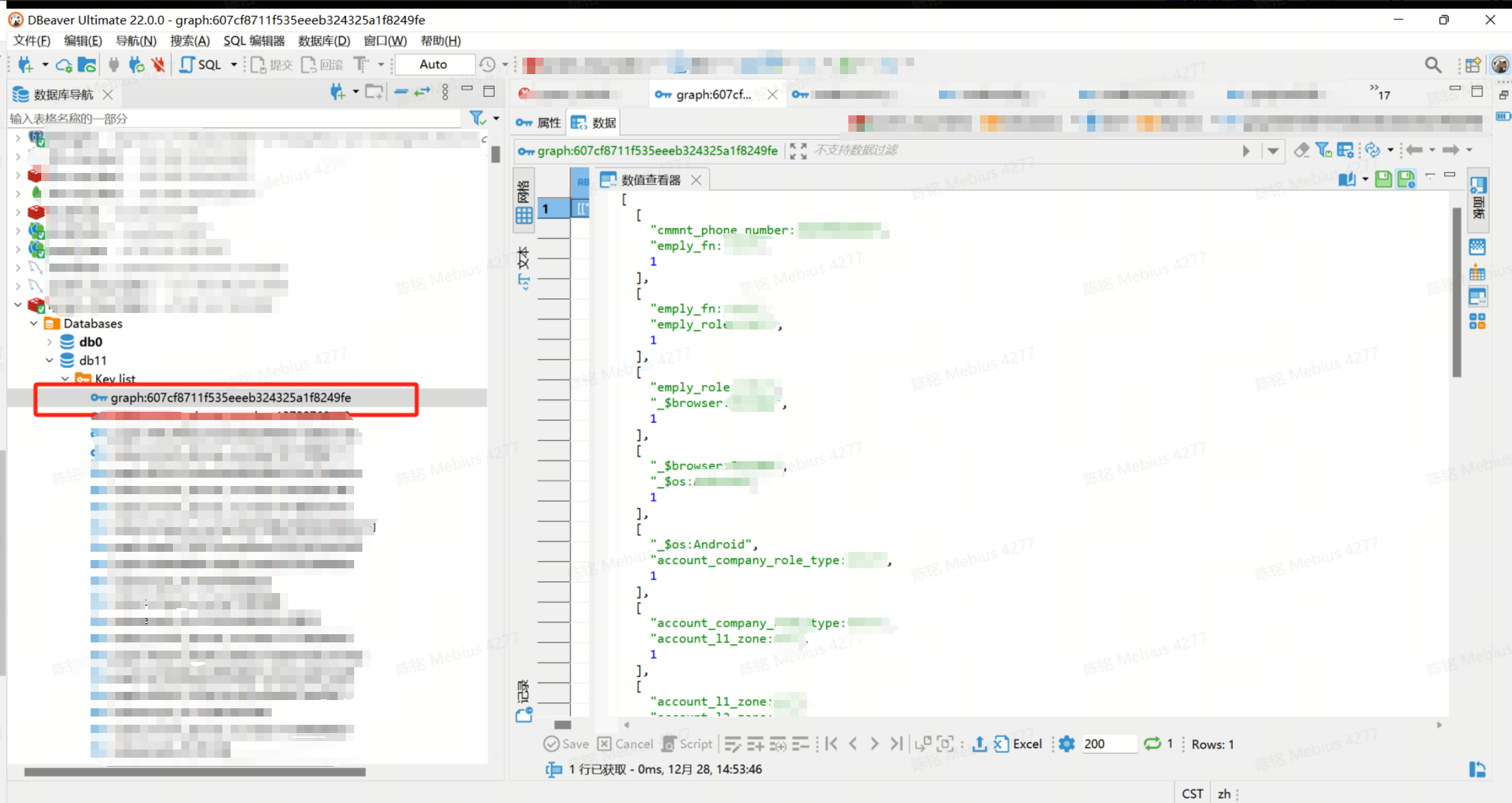
查询语句没啥好说的,精确的节点倒排索引出具体的无向图,根据node_key就可以获取到
模糊查询先通过节点类型获取到node_key,再获取到无向图。但这个过程会因为模糊查询的增大而大大提升时间复杂度 (产生大量笛卡尔积)
存取源码
import itertools
import json
import logging
import multiprocessing
import time
from itertools import combinations
from tornado import concurrent
from graph.build import uuid, build_graph
from rdb.conn import get_redis_conn
conn = get_redis_conn()
node_to_graph = "node_to_graph"
def remove_all():
conn.flushdb()
def node_key_idx(node: str):
node = node.split(':')[0]
return f"node:{node}"
def node_key(node):
return f"node:{node}"
def save_graph(g):
edges = g.edges(data=True)
edges = [(e[0], e[1], e[2]["weight"]) for e in edges]
g_nodes = json.dumps(edges)
g_key = f"graph:{uuid(g)}"
conn.set(g_key, g_nodes)
# 使用哈希表存储节点与图的对应关系
nodes = [e[0] for e in edges]
nodes += [e[1] for e in edges]
nodes = set(nodes)
for node in nodes:
nk = node_key(node)
nki = node_key_idx(node)
conn.sadd(nk, g_key)
conn.sadd(nki, nk)
# 根据节点反查包含该节点的图
def find_graph(node):
nk = node_key(node)
g_keys = conn.smembers(nk)
if len(g_keys) > 0:
gs = [(gk, build_graph(json.loads(conn.get(gk)))) for gk in g_keys]
return gs
else:
return []
# 根据多个节点反查包含该节点的图
def find_graphs(*nodes):
if len(nodes) == 1:
return find_graph(nodes[0])
nks = [node_key(nk) for nk in nodes]
g_keys = conn.sinter(nks)
if len(g_keys) > 0:
gs = [(gk, build_graph(json.loads(conn.get(gk)))) for gk in g_keys]
return gs
else:
return []
def inter_run(ts):
nodes = tuple([t[0] for t in ts])
gks_list = [t[1] for t in ts]
set_list = [set(sublist) for sublist in gks_list]
intersection = set_list[0].intersection(*set_list[1:])
if intersection:
return (nodes, intersection)
return None
def duplicate_nodes(*noed_key_idxs, build_graph=False):
time1 = time.time()
# 是否模糊筛选
keys_with_prefixs = []
for noed_key_idx in noed_key_idxs:
split_ = noed_key_idx.split(':')
if len(split_) > 2:
new_noed_key_idx = split_[0] + ':' + split_[1]
keys_with_prefix = conn.smembers(new_noed_key_idx)
keys_with_prefix = [k for k in keys_with_prefix if k == noed_key_idx]
else:
keys_with_prefix = conn.smembers(noed_key_idx)
keys_with_prefixs.append(keys_with_prefix)
# 过滤出值为 set 且大小大于 2 的 key
gts = []
for keys_with_prefix in keys_with_prefixs:
keys = [(key, list(conn.smembers(key))) for key in keys_with_prefix if conn.scard(key) > 2]
gts.append(keys)
# 找出具有交集的元组对
cobs = list(itertools.product(*gts))
total = len(cobs)
# logging.info("所有命中的可能组合数量 {}".format(str(total)))
num = 0
num1 = 0
res = []
for cob in cobs:
inters = inter_run(cob)
num += 1
if inters is not None:
num1 += len(inters[1])
res.append((inters[0], quick_build_g(inters[1]) if build_graph else inters[1]))
# logging.info("已命中潜在用户数量 {} 已处理组合数量 {}/{}".format(str(num1), str(num), str(total)))
logging.info("Redis所有潜在用户的数量 {}".format(str(num1)))
logging.info("Redis倒排索引总耗时 {}s".format(str(time.time() - time1)))
return res
def bg(gk):
return build_graph(json.loads(conn.get(gk)))
def quick_build_g(gks):
with concurrent.futures.ThreadPoolExecutor(max_workers=100) as executor:
# 提交任务给线程池
futures = [executor.submit(bg, gk) for gk in gks]
gs = [future.result() for future in futures]
return gs
基于Neo4j的实现
Neo4j存储数据结构
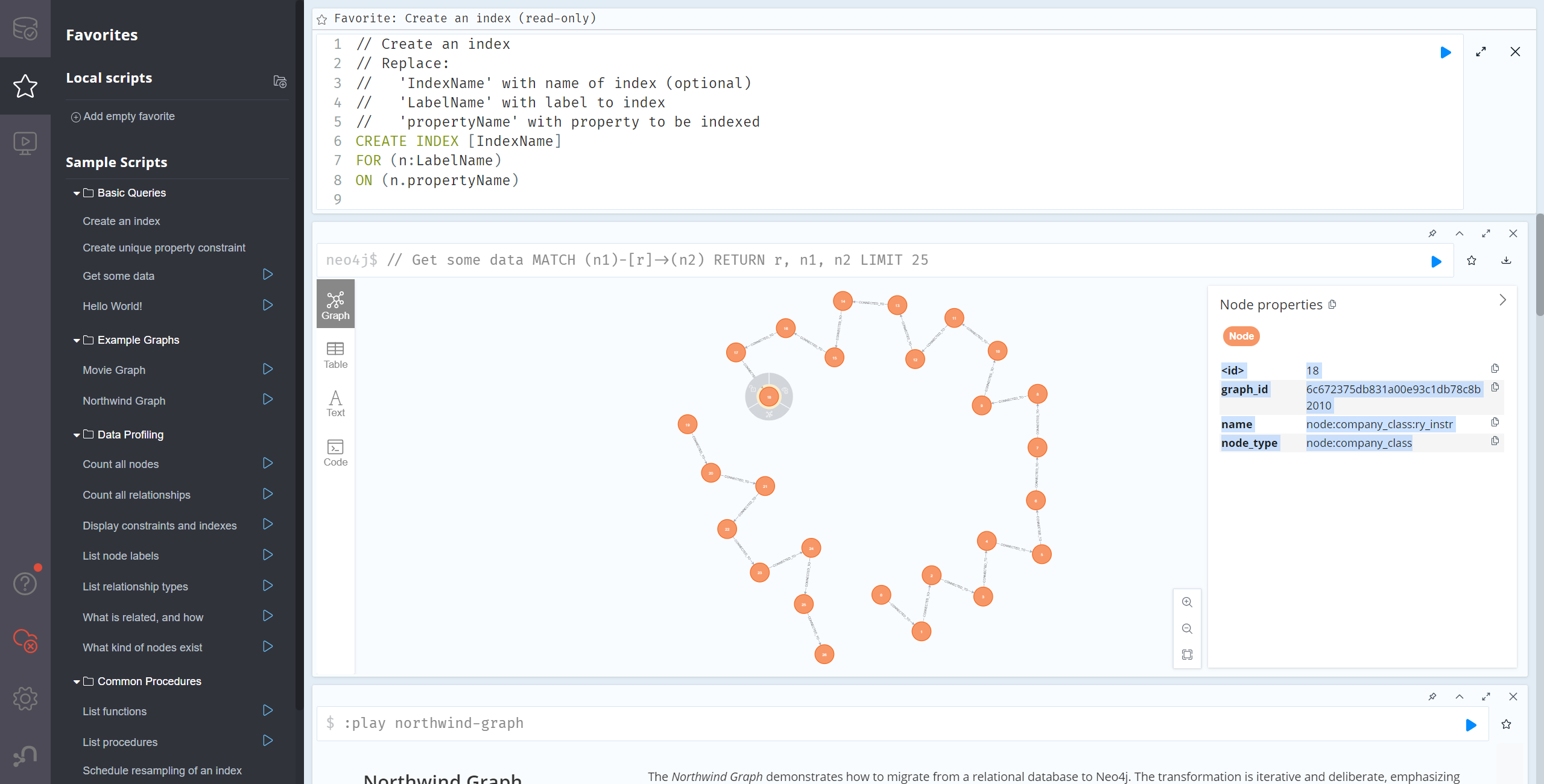
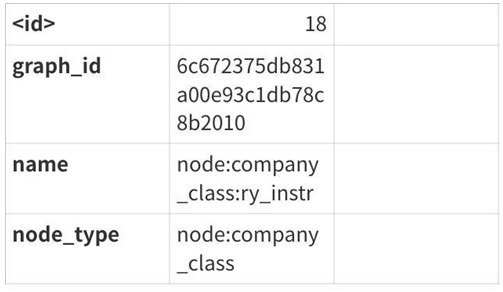
无向图的每个节点都会带上属性:
- graph_id,对应redis的graph_key
- name,节点名字
- node_type,对应redis的节点类型
精确查询
MATCH (n:Node)
WHERE n.name IN $node_names
WITH n.graph_id AS graph_id,count(distinct n) AS node_count
where node_count = $node_count
WITH graph_id
MATCH (node:Node {graph_id: graph_id})
WITH node.graph_id AS graph_id, collect(DISTINCT node.name) AS nodes
RETURN graph_id, nodes
模糊查询
MATCH (n:Node)
WHERE n.node_type IN $node_names
// 找到具备上述节点的图,且以graph_id未分组,要求上述节点的数量也要符合模糊条件的数量
WITH n.graph_id AS graph_id,COUNT(DISTINCT n) AS node_count
WHERE node_count = $node_count
// 这些graph_id代表了都具备上述全部节点的图
WITH DISTINCT graph_id @@@exact_node_names
MATCH (node:Node {graph_id: graph_id})
// 对这些图,找出模糊条件中匹配的节点
WHERE node.node_type in $node_names
// 以graph_id未分组,把这些节点的节点名进行聚合成列表
WITH node.graph_id as graph_id, collect(node.name) AS node_names
WITH node_names, collect(DISTINCT graph_id) AS graph_ids
// 此时用节点名列表分组,就可以把相同节点名条件的图聚合在一起
UNWIND graph_ids AS graph_id
// 把这个graph_ids炸裂开
WITH node_names, graph_id
// 获取到这些graph_id的节点
MATCH (node:Node {graph_id: graph_id})
// 返回最终结果
RETURN DISTINCT node_names, graph_id, collect(DISTINCT node.name) AS nodes
存取源码
import logging
import time
from neo4j import GraphDatabase
from py2neo import Graph, Node, Relationship
logging.basicConfig(format='%(asctime)s %(message)s', level=logging.INFO)
from graph.build import uuid, build_halo_graph
uri = "bolt://localhost:7687" # Neo4j 服务器的地址
username = "neo4j" # 替换为你的用户名
password = "185123456" # 替换为你的密码
graph = Graph(uri, auth=(username, password))
# 连接到数据库驱动
driver = GraphDatabase.driver(uri, auth=(username, password))
def save_graph_neo4j(g):
g_id = uuid(g)
nodes = {}
for n in list(g.nodes()):
node_name = 'node:' + n
node_type = 'node:' + n.split(':')[0]
node0 = Node("Node", name=node_name, graph_id=g_id, node_type=node_type)
nodes[n] = node0
rels = [Relationship(nodes[source], "CONNECTED_TO", nodes[target], graph_id=g_id) for source, target, weight in
list(g.edges(data='weight', default=1))]
# 将节点和关系添加到图数据库中
tx = graph.begin()
for node in nodes.values():
tx.create(node)
for rel in rels:
tx.create(rel)
tx.commit()
def del_all_neo4j():
graph.delete_all()
def find_graph_neo(*node_names, build_graph=False):
time1 = time.time()
node_names = list(node_names)
# 编写 Cypher 查询语句
cypher_query = """
MATCH (n:Node)
WHERE n.name IN $node_names
WITH n.graph_id AS graph_id,count(distinct n) AS node_count
where node_count = $node_count
WITH graph_id
MATCH (node:Node {graph_id: graph_id})
WITH node.graph_id AS graph_id, collect(DISTINCT node.name) AS nodes
RETURN graph_id, nodes
"""
# 执行查询
result = graph.run(cypher_query, node_names=node_names, node_count=len(node_names))
result = list(result)
logging.info("Neo4j所有潜在用户的数量 {}".format(str(len(result))))
# 处理查询结果
graphs = {record['graph_id']: record['nodes'] for record in result}
graphs = {graph_id: build_halo_graph(graphs[graph_id]) if build_graph else graphs[graph_id] for graph_id in graphs}
logging.info("Neo4j倒排索引总耗时 {}s".format(str(time.time() - time1)))
return graphs
def find_graph_neo_ambi(*node_names, build_graph=False):
time1 = time.time()
node_names0 = list(node_names)
exact_node_names = []
node_names = []
for nm in node_names0:
split = nm.split(':')
if len(split) > 2:
node_names.append(split[0] + ':' + split[1])
exact_node_names.append(nm)
else:
node_names.append(nm)
# 编写 Cypher 查询语句
cypher_query = """
MATCH (n:Node)
WHERE n.node_type IN $node_names
// 找到具备上述节点的图,且以graph_id未分组,要求上述节点的数量也要符合模糊条件的数量
WITH n.graph_id AS graph_id,COUNT(DISTINCT n) AS node_count
WHERE node_count = $node_count
// 这些graph_id代表了都具备上述全部节点的图
WITH DISTINCT graph_id @@@exact_node_names
MATCH (node:Node {graph_id: graph_id})
// 对这些图,找出模糊条件中匹配的节点
WHERE node.node_type in $node_names
// 以graph_id未分组,把这些节点的节点名进行聚合成列表
WITH node.graph_id as graph_id, collect(node.name) AS node_names
WITH node_names, collect(DISTINCT graph_id) AS graph_ids
// 此时用节点名列表分组,就可以把相同节点名条件的图聚合在一起
UNWIND graph_ids AS graph_id
// 把这个graph_ids炸裂开
WITH node_names, graph_id
// 获取到这些graph_id的节点
MATCH (node:Node {graph_id: graph_id})
// 返回最终结果
RETURN DISTINCT node_names, graph_id, collect(DISTINCT node.name) AS nodes
""".replace('@@@exact_node_names','''
MATCH (exact_node:Node {graph_id: graph_id})
WHERE exact_node.name in $exact_node_names
WITH DISTINCT exact_node.graph_id AS graph_id''' if len(exact_node_names)>0 else '')
cypher_sql = cypher_query\
.replace('$node_names','[' + ', '.join(['"' + n + '"' for n in node_names]) + ']')\
.replace('$exact_node_names','[' + ', '.join(['"' + n + '"' for n in exact_node_names]) + ']')\
.replace('$node_count', str(len(node_names)))
logging.info(f'cypher_sql:\n{cypher_sql}')
# 执行查询
result = graph.run(cypher_query, node_names=node_names,exact_node_names=exact_node_names, node_count=len(node_names))
result = list(result)
logging.info("Neo4j所有潜在用户的数量 {}".format(str(len(result))))
# 处理查询结果
graphs = {(tuple(record['node_names']), record['graph_id']): record['nodes'] for record in result}
graphs = {graph_id: build_halo_graph(graphs[graph_id]) if build_graph else graphs[graph_id] for graph_id in graphs}
logging.info("Neo4j倒排索引总耗时 {}s".format(str(time.time() - time1)))
return graphs
def create_idx():
graph.run('''
CREATE INDEX
FOR (n:Node)
ON (n.name)
''')
graph.run('''
CREATE INDEX
FOR (n:Node)
ON (n.node_type)
''')
graph.run('''
CREATE INDEX
FOR (n:Node)
ON (n.graph_id)
''')
基准测试
使用工单的自然人数据,共计50223人,分别对两者进行压测
很明显可以看到,一旦模糊搜索数量只要一多,redis完全无法处理好图的搜索
| 查询类型 | 条件数量 | redis/s | neo4j/s |
|---|---|---|---|
| 精确查询 | 2 | 0.14 | 0.17 |
| 精确查询 | 3 | 0.02 | 0.03 |
| 精确查询 | 6 | 0.09 | 0.06 |
| 模糊查询 | 2 | 1.29 | 8.53 |
| 模糊查询 | 3 | 34.68 | 8.93 |
| 模糊查询 | 4 | 679.06 | 10.80 |
| 模糊查询 | 5 | 5537.46 | 10.62 |
import logging
from graph.build import draw_graph
from holo.query import save_all_user_neo4j
from neo.neo_service import find_graph_neo, find_graph_neo_ambi
from rdb.redis_service import duplicate_nodes
logging.basicConfig(format='%(asctime)s %(message)s', level=logging.INFO)
if __name__ == '__main__':
logging.info("========== 精确匹配,条件数 2 ==========")
duplicate_nodes('node:superir_company_name:抚州xxxx有限公司','node:emply_role:老板')
find_graph_neo('node:superir_company_name:抚州xxxx有限公司','node:emply_role:老板')
logging.info("========== 精确匹配,条件数 3 ==========")
duplicate_nodes('node:account_city:乌鲁木齐市',
'node:account_l2_zone:新疆',
'node:account_l1_zone:西区')
find_graph_neo('node:account_city:乌鲁木齐市',
'node:account_l2_zone:新疆',
'node:account_l1_zone:西区')
logging.info("========== 精确匹配,条件数 6 ==========")
duplicate_nodes('node:account_city:乌鲁木齐市',
'node:account_l2_zone:新疆',
'node:account_l1_zone:西区',
'node:account_company_role_type:管理者',
'node:emply_role:管理员',
'node:_$os:Android')
find_graph_neo('node:account_city:乌鲁木齐市',
'node:account_l2_zone:新疆',
'node:account_l1_zone:西区',
'node:account_company_role_type:管理者',
'node:emply_role:管理员',
'node:_$os:Android')
logging.info("========== 模糊匹配,条件数 2 ==========")
duplicate_nodes('node:account_city','node:account_l2_zone')
find_graph_neo_ambi('node:account_city','node:account_l2_zone')
logging.info("========== 模糊匹配,条件数 3 ==========")
duplicate_nodes('node:account_city','node:account_l2_zone','node:emply_role')
find_graph_neo_ambi('node:account_city','node:account_l2_zone','node:emply_role')
logging.info("========== 模糊匹配,条件数 4 ==========")
duplicate_nodes('node:account_city','node:account_l2_zone','node:emply_role','node:_$os')
find_graph_neo_ambi('node:account_city','node:account_l2_zone','node:emply_role','node:_$os')
logging.info("========== 模糊匹配,条件数 5 ==========")
duplicate_nodes('node:account_city','node:account_l2_zone','node:emply_role','node:_$os','node:account_l1_zone')
find_graph_neo_ambi('node:account_city','node:account_l2_zone','node:emply_role','node:_$os','node:account_l1_zone')
logging.info("========== 模糊匹配,条件数 6 ==========")
find_graph_neo_ambi('node:_$browser', 'node:account_city', 'node:account_l2_zone', 'node:emply_role', 'node:_$os',
'node:account_l1_zone', 'node:superir_company_name')
logging.info("========== 模糊匹配,条件数 7 ==========")
find_graph_neo_ambi('node:account_certify_enginer_type', 'node:_$browser', 'node:account_city',
'node:account_l2_zone', 'node:emply_role', 'node:_$os', 'node:account_l1_zone',
'node:superir_company_name')
logging.info("========== 模糊匹配,条件数 8 ==========")
find_graph_neo_ambi('node:account_type', 'node:_$model', 'node:account_certify_enginer_type', 'node:_$browser',
'node:account_city', 'node:account_l2_zone', 'node:emply_role', 'node:_$os',
'node:account_l1_zone', 'node:superir_company_name')
logging.info("========== 模糊匹配,条件数 9 ==========")
find_graph_neo_ambi('node:company_sub_type', 'node:account_type', 'node:_$model',
'node:account_certify_enginer_type', 'node:_$browser', 'node:account_city',
'node:account_l2_zone', 'node:emply_role', 'node:_$os', 'node:account_l1_zone',
'node:superir_company_name')
logging.info("========== 模糊匹配,条件数 10 ==========")
find_graph_neo_ambi('node:cmmnt_phone_number', 'node:company_sub_type', 'node:account_type', 'node:_$model',
'node:account_certify_enginer_type', 'node:_$browser', 'node:account_city',
'node:account_l2_zone', 'node:emply_role', 'node:_$os', 'node:account_l1_zone',
'node:superir_company_name')
logging.info("========== 模糊匹配,条件数 25 ==========")
find_graph_neo_ambi("node:cmmnt_phone_number",
"node:emply_fn",
"node:emply_cert",
"node:emply_role",
"node:_$browser",
"node:_$os",
"node:account_certify_enginer_type",
"node:account_company_role_type",
"node:account_l1_zone",
"node:account_l2_zone",
"node:account_zone_sale_name",
"node:account_nation",
"node:account_provnce",
"node:account_city",
"node:account_type",
"node:company_name",
"node:company_type",
"node:company_sub_type",
"node:company_class",
"node:_$manufacturer",
"node:_$model",
"node:superir_company_name",
"node:superir_company_type",
"node:superir_company_sub_type",
"node:_$carrier",
)
logging.info("========== 模糊匹配,条件数 25 ==========")
find_graph_neo_ambi("node:cmmnt_phone_number",
"node:emply_fn",
"node:emply_cert",
"node:emply_role:老板",
"node:_$browser",
"node:_$os",
"node:account_certify_enginer_type",
"node:account_company_role_type",
"node:account_l1_zone",
"node:account_l2_zone",
"node:account_zone_sale_name",
"node:account_nation",
"node:account_provnce",
"node:account_city",
"node:account_type",
"node:company_name",
"node:company_type",
"node:company_sub_type",
"node:company_class",
"node:_$manufacturer:XIAOMI",
"node:_$model",
"node:superir_company_name",
"node:superir_company_type",
"node:superir_company_sub_type",
"node:_$carrier",
)
评论区