

onnx安装
pip install onnx
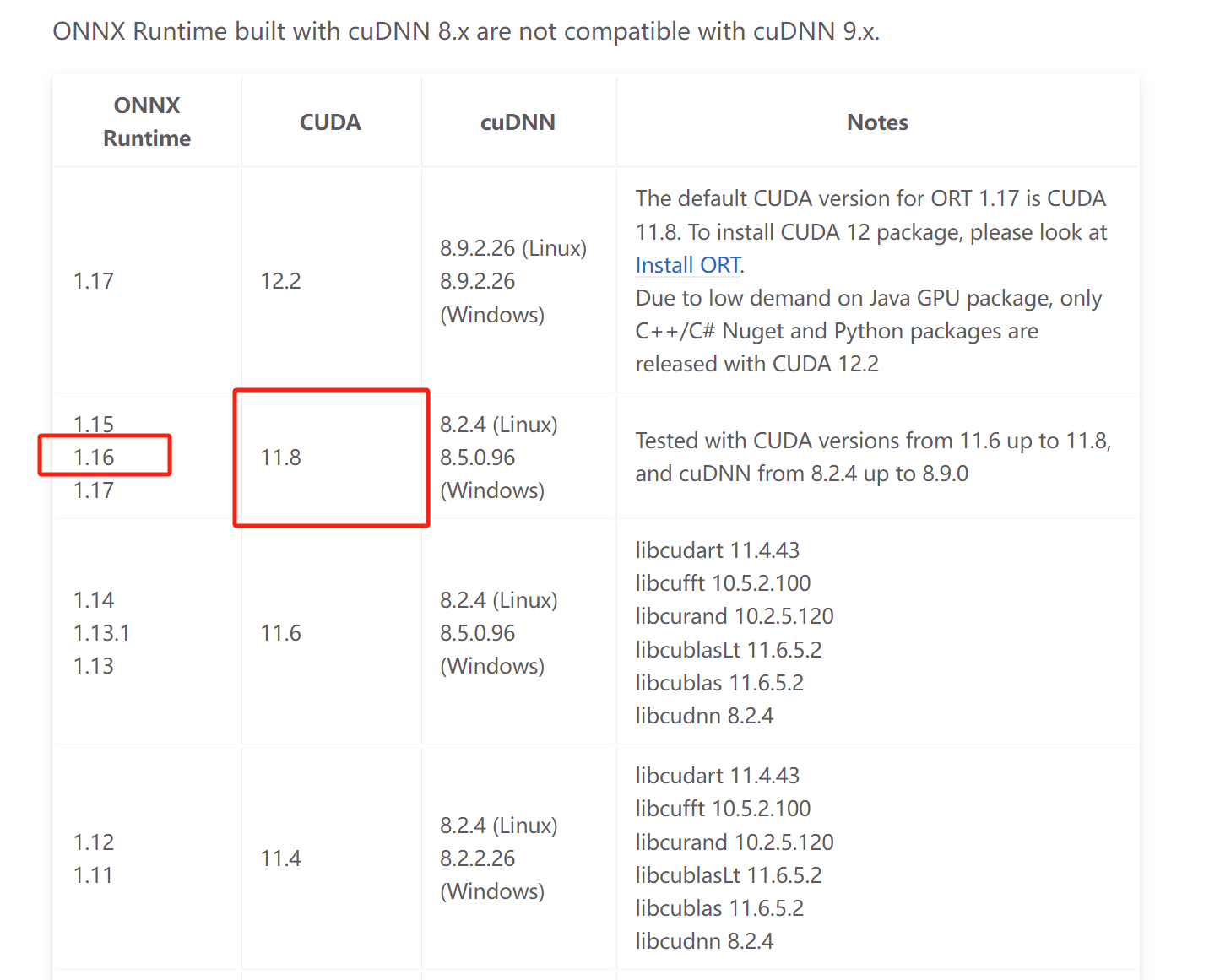
pip install onnxruntime-gpu==1.16
ort对应cuda版本 我是cuda11.8,此处安装1.16的onnxruntime-gpu
转换
def pytorch2onnx(task_type, onnx_model_path):
train_conf = get_train_conf(task_type)
img_size = train_conf['img_size']
model_type = train_conf['model_type']
model = get_model(task_type=task_type, model_type=model_type).cuda()
_pytorch2onnx(model,onnx_model_path,img_size)
# 重点是这个方法,传入一个torch模型,指定好输入来传递一遍计算图
def _pytorch2onnx(model:nn.Module, onnx_model_path,img_size=1024):
model=model.cuda()
input = torch.FloatTensor(1, 3, img_size, img_size).cuda()
torch.onnx.export(model, input, onnx_model_path,
# opset_version=16,
# 折叠常量,输出的模型文件更小
do_constant_folding=True,
# 指定输入输出的名字,有多个输入输出时有用,比如bert有两个输入。这里的模型是resnet都是单个输入输出的
input_names=['input'],
output_names=['output'],
# 指定输入输出的第0为是bs维度,即可变长度的维度
dynamic_axes={'input': {0: 'batch_size'},
'output': {0: 'batch_size'}}
)
def export(task_type='merge'):
onnx_model_dir = f'{script_path}/model/{task_type}'
if not os.path.exists(onnx_model_dir):
os.makedirs(onnx_model_dir)
if task_type=='merge':
model = get_merge_model().cuda()
else:
assert task_type in ORDERED_TASK_TYPES
model = get_model(task_type=task_type, model_type='resnet50').cuda()
onnx_model_path=f'{onnx_model_dir}/resnet.onnx'
_pytorch2onnx(model, onnx_model_path=onnx_model_path)
onnx_model = onnx.load(onnx_model_path)
onnx.checker.check_model(onnx_model)
推理
# {"cudnn_conv_algo_search": "DEFAULT"}可以让卷积操作更快
def get_session(model_path, device='cuda'):
providers = [
("CUDAExecutionProvider", {"cudnn_conv_algo_search": "DEFAULT"}),
'CPUExecutionProvider',
] if device == 'cuda' else ['CPUExecutionProvider']
# 打开日志,这里关闭
opts = onnxruntime.SessionOptions()
opts.enable_profiling = False
session = onnxruntime.InferenceSession(model_path, opts, providers=providers)
return session
# 上述导出模型指定了输入输出名,这里就可以去详细传入/获取对应的tensor
def onnx_infer_by_session(session: InferenceSession, input: Tensor):
pred = torch.from_numpy(session.run(['output'], {'input': input.numpy()})[0])
gc.collect()
return pred
def onnx_infer_by_path(onnx_model_path, input: Tensor, device='cuda'):
session = get_session(onnx_model_path, device)
return onnx_infer_by_session(session, input)
评论区