

Dstream 入门
WordCount 案例实操
需求: 使用 netcat 工具向 9999 端口不断的发送数据,通过 SparkStreaming 读取端口数据并统计不同单词出现的次数
添加依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>3.0.0</version>
</dependency>
编写代码
编写一个Receiver,监听hadoop100主机发来的消息
package ltd.cmjava.spark.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreaming01_WordCount {
def main(args: Array[String]): Unit = {
// TODO 创建环境对象
// StreamingContext创建时,需要传递两个参数
// 第一个参数表示环境配置
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
// 第二个参数表示批量处理的周期(采集周期)
val ssc = new StreamingContext(sparkConf, Seconds(3))
// TODO 逻辑处理
// 获取端口数据
val lines: ReceiverInputDStream[String] = ssc.socketTextStream("hadoop100", 9999)
val words = lines.flatMap(_.split(" "))
val wordToOne = words.map((_,1))
val wordToCount: DStream[(String, Int)] = wordToOne.reduceByKey(_+_)
wordToCount.print()
// 由于SparkStreaming采集器是长期执行的任务,所以不能直接关闭
// 如果main方法执行完毕,应用程序也会自动结束。所以不能让main执行完毕
//ssc.stop()
// 1. 启动采集器
ssc.start()
// 2. 等待采集器的关闭
ssc.awaitTermination()
}
}
启动程序并通过netcat 发送数据
在hadoop100模拟发送消息
nc -lp 9999
hello spark
WordCount 解析
Discretized Stream 是 Spark Streaming 的基础抽象,代表持续性的数据流和经过各种 Spark 原语操作后的结果数据流。在内部实现上,DStream 是一系列连续的 RDD 来表示。每个RDD 含有一段时间间隔内的数据。

对数据的操作也是按照RDD 为单位来进行的
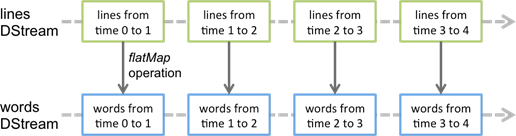
计算过程由 Spark Engine 来完成

DStream 创建
RDD 队列
用法及说明
测试过程中,可以通过使用 ssc.queueStream(queueOfRDDs)来创建 DStream,每一个推送到这个队列中的RDD,都会作为一个DStream 处理。
案例实操
需求: 循环创建几个 RDD,将RDD 放入队列。通过 SparkStream 创建 Dstream,计算WordCount
编写代码
package ltd.cmjava.spark.streaming
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import scala.collection.mutable
object SparkStreaming02_Queue {
def main(args: Array[String]): Unit = {
// TODO 创建环境对象
// StreamingContext创建时,需要传递两个参数
// 第一个参数表示环境配置
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
// 第二个参数表示批量处理的周期(采集周期)
val ssc = new StreamingContext(sparkConf, Seconds(3))
val rddQueue = new mutable.Queue[RDD[Int]]()
val inputStream = ssc.queueStream(rddQueue,oneAtATime = false)
val mappedStream = inputStream.map((_,1))
val reducedStream = mappedStream.reduceByKey(_ + _)
reducedStream.print()
ssc.start()
for (i <- 1 to 5) {
rddQueue += ssc.sparkContext.makeRDD(1 to 300, 10)
Thread.sleep(2000)
}
ssc.awaitTermination()
}
}
结果展示
-------------------------------------------
Time: 1676171955000 ms
-------------------------------------------
(224,1)
(160,1)
(96,1)
(112,1)
(16,1)
(80,1)
(48,1)
(128,1)
(240,1)
(208,1)
...
-------------------------------------------
Time: 1676171958000 ms
-------------------------------------------
(224,2)
(160,2)
(96,2)
(112,2)
(16,2)
(80,2)
(48,2)
(128,2)
(240,2)
(208,2)
...
-------------------------------------------
Time: 1676171961000 ms
-------------------------------------------
(224,1)
(160,1)
(96,1)
(112,1)
(16,1)
(80,1)
(48,1)
(128,1)
(240,1)
(208,1)
...
自定义数据源
用法及说明
需要继承Receiver,并实现 onStart、onStop 方法来自定义数据源采集。
案例实操
需求: 自定义数据源,实现监控某个端口号,获取该端口号内容。
自定义数据源
package ltd.cmjava.spark.streaming
import java.util.Random
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.dstream.ReceiverInputDStream
import org.apache.spark.streaming.receiver.Receiver
import org.apache.spark.streaming.{Seconds, StreamingContext}
import scala.collection.mutable
object SparkStreaming03_DIY {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(3))
val messageDS: ReceiverInputDStream[String] = ssc.receiverStream(new MyReceiver())
messageDS.print()
ssc.start()
ssc.awaitTermination()
}
/*
自定义数据采集器
1. 继承Receiver,定义泛型, 传递参数
2. 重写方法
*/
class MyReceiver extends Receiver[String](StorageLevel.MEMORY_ONLY) {
private var flg = true
override def onStart(): Unit = {
new Thread(new Runnable {
override def run(): Unit = {
while ( flg ) {
val message = "采集的数据为:" + new Random().nextInt(10).toString
store(message)
Thread.sleep(500)
}
}
}).start()
}
override def onStop(): Unit = {
flg = false;
}
}
}
Kafka 数据源(面试、开发重点)
版本选型
ReceiverAPI:需要一个专门的Executor 去接收数据,然后发送给其他的 Executor 做计算。存在的问题,接收数据的Executor 和计算的Executor 速度会有所不同,特别在接收数据的Executor速度大于计算的Executor 速度,会导致计算数据的节点内存溢出。早期版本中提供此方式,当前版本不适用
DirectAPI:是由计算的Executor 来主动消费Kafka 的数据,速度由自身控制。
Kafka 0-8 Receiver 模式(当前版本不适用)
需求: 通过 SparkStreaming 从 Kafka 读取数据,并将读取过来的数据做简单计算,最终打印到控制台。
导入依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-8_2.11</artifactId>
<version>2.4.5</version>
</dependency>
编写代码
package ltd.cmjava.spark.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.ReceiverInputDStream
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
object ReceiverAPI {
def main(args: Array[String]): Unit = {
//1.创建 SparkConf
val sparkConf: SparkConf = new SparkConf().setAppName("ReceiverWordCount").setMaster("local[*]")
//2.创建 StreamingContext
val ssc = new StreamingContext(sparkConf, Seconds(3))
//3.读取 Kafka 数据创建 DStream(基于 Receive 方式)
val kafkaDStream: ReceiverInputDStream[(String, String)] = KafkaUtils.createStream(ssc,
"hadoop100:2181,hadoop101:2181,hadoop102:2181", "cm",
Map[String, Int]("cm" -> 1))
//4.计算 WordCount
kafkaDStream.map { case (_, value) => (value, 1)
}.reduceByKey(_ + _)
.print()
//5.开启任务
ssc.start()
ssc.awaitTermination()
}
}
Kafka 0-8 Direct 模式(当前版本不适用)
需求: 通过 SparkStreaming 从Kafka 读取数据,并将读取过来的数据做简单计算,最终打印到控制台。
导入依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-8_2.11</artifactId>
<version>2.4.5</version>
</dependency>
编写代码(自动维护offset)
package ltd.cmjava.spark.streaming
import kafka.serializer.StringDecoder
import org.apache.kafka.clients.consumer.ConsumerConfig
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
object DirectAPIAuto02 {
val getSSC1: () => StreamingContext = () => {
val sparkConf: SparkConf = new
SparkConf().setAppName("ReceiverWordCount").setMaster("local[*]")
val ssc = new StreamingContext(sparkConf, Seconds(3))
ssc
}
def getSSC: StreamingContext = {
//1.创建 SparkConf
val sparkConf: SparkConf = new SparkConf().setAppName("ReceiverWordCount").setMaster("local[*]")
//2.创建 StreamingContext
val ssc = new StreamingContext(sparkConf, Seconds(3))
//设置 CK
ssc.checkpoint("./ck2")
//3.定义 Kafka 参数
val kafkaPara: Map[String, String] = Map[String, String](ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG ->
"hadoop100:9092,hadoop101:9092,hadoop102:9092", ConsumerConfig.GROUP_ID_CONFIG -> "cm"
)
//4.读取 Kafka 数据
val kafkaDStream: InputDStream[(String, String)] = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc,
kafkaPara, Set("cm"))
//5.计算 WordCount
kafkaDStream.map(_._2)
.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
.print()
//6.返回数据
ssc
}
def main(args: Array[String]): Unit = {
//获取 SSC
val ssc: StreamingContext = StreamingContext.getActiveOrCreate("./ck2", () => getSSC)
//开启任务 ssc.start()
ssc.awaitTermination()
}
}
编写代码(手动维护offset)
package ltd.cmjava.spark.streaming
import kafka.common.TopicAndPartition
import kafka.message.MessageAndMetadata
import kafka.serializer.StringDecoder
import org.apache.kafka.clients.consumer.ConsumerConfig
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka.{HasOffsetRanges, KafkaUtils, OffsetRange}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object DirectAPIHandler {
def main(args: Array[String]): Unit = {
//1.创建 SparkConf
val sparkConf: SparkConf = new SparkConf().setAppName("ReceiverWordCount").setMaster("local[*]")
//2.创建 StreamingContext
val ssc = new StreamingContext(sparkConf, Seconds(3))
//3.Kafka 参数
val kafkaPara: Map[String, String] = Map[String, String](ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG ->
"hadoop100:9092,hadoop101:9092,hadoop102:9092", ConsumerConfig.GROUP_ID_CONFIG -> "cm"
)
//4.获取上一次启动最后保留的 Offset=>getOffset(MySQL)
val fromOffsets: Map[TopicAndPartition, Long] = Map[TopicAndPartition, Long](TopicAndPartition("cm", 0) -> 20)
//5.读取 Kafka 数据创建 DStream
val kafkaDStream: InputDStream[String] = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder, String](ssc,
kafkaPara, fromOffsets,
(m: MessageAndMetadata[String, String]) => m.message())
//6.创建一个数组用于存放当前消费数据的 offset 信息
var offsetRanges = Array.empty[OffsetRange]
//7.获取当前消费数据的 offset 信息
val wordToCountDStream: DStream[(String, Int)] = kafkaDStream.transform {
rdd =>
offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
rdd
}.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
//8.打印 Offset 信息
wordToCountDStream.foreachRDD(rdd => {
for (o <- offsetRanges) {
println(s"${o.topic}:${o.partition}:${o.fromOffset}:${o.untilOffset}")
}
rdd.foreach(println)
})
//9.开启任务
ssc.start()
ssc.awaitTermination()
}
}
Kafka 0-10 Direct 模式
需求: 通过 SparkStreaming 从Kafka 读取数据,并将读取过来的数据做简单计算,最终打印到控制台。
导入依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.10.1</version>
</dependency>
编写代码
package ltd.cmjava.spark.streaming
import java.util.Random
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.dstream.{InputDStream, ReceiverInputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.receiver.Receiver
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreaming04_Kafka {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(3))
val kafkaPara: Map[String, Object] = Map[String, Object](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "hadoop100:9092,hadoop101:9092,hadoop102:9092",
ConsumerConfig.GROUP_ID_CONFIG -> "cm",
"key.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer",
"value.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer"
)
val kafkaDataDS: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](Set("cm"), kafkaPara)
)
kafkaDataDS.map(_.value()).print()
ssc.start()
ssc.awaitTermination()
}
}
查看Kafka 消费进度
bin/kafka-consumer-groups.sh --describe --bootstrap-server hadoop100:9092 --group cm
DStream 转换
DStream 上的操作与 RDD 的类似,分为Transformations(转换)和Output Operations(输出)两种,此外转换操作中还有一些比较特殊的原语,如:updateStateByKey()、transform()以及各种Window 相关的原语。
无状态转化操作
无状态转化操作就是把简单的RDD 转化操作应用到每个批次上,也就是转化DStream 中的每一个RDD。部分无状态转化操作列在了下表中。注意,针对键值对的DStream 转化操作(比如 reduceByKey())要添加 import StreamingContext._才能在 Scala 中使用。

需要记住的是,尽管这些函数看起来像作用在整个流上一样,但事实上每个DStream 在内部是由许多RDD(批次)组成,且无状态转化操作是分别应用到每个 RDD 上的。
例如:reduceByKey()会归约每个时间区间中的数据,但不会归约不同区间之间的数据。
Transform
Transform 允许 DStream 上执行任意的RDD-to-RDD 函数。即使这些函数并没有在DStream 的 API 中暴露出来,通过该函数可以方便的扩展 Spark API。该函数每一批次调度一次。其实也就是对 DStream 中的 RDD 应用转换。
package ltd.cmjava.spark.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreaming06_State_Transform {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(3))
val lines = ssc.socketTextStream("hadoop100", 9999)
// transform方法可以将底层RDD获取到后进行操作
// 1. DStream功能不完善
// 2. 需要代码周期性的执行
// Code : Driver端
val newDS: DStream[String] = lines.transform(
rdd => {
// Code : Driver端,(周期性执行)
rdd.map(
str => {
// Code会在 Executor端 执行
str
}
)
}
)
newDS.print()
// Code : Driver端
val newDS1: DStream[String] = lines.map(
data => {
// Code会在 Executor端 执行
data
}
)
newDS1.print()
ssc.start()
ssc.awaitTermination()
}
}
join
两个流之间的join 需要两个流的批次大小一致,这样才能做到同时触发计算。计算过程就是对当前批次的两个流中各自的RDD 进行 join,与两个 RDD 的 join 效果相同。
package ltd.cmjava.spark.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreaming06_State_Join {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(5))
val data9999 = ssc.socketTextStream("hadoop100", 9999)
val data8888 = ssc.socketTextStream("hadoop100", 8888)
val map9999: DStream[(String, Int)] = data9999.map((_,9))
val map8888: DStream[(String, Int)] = data8888.map((_,8))
// 所谓的DStream的Join操作,其实就是两个RDD的join
val joinDS: DStream[(String, (Int, Int))] = map9999.join(map8888)
joinDS.print()
ssc.start()
ssc.awaitTermination()
}
}
有状态转化操作
UpdateStateByKey
UpdateStateByKey 原语用于记录历史记录,有时,我们需要在 DStream 中跨批次维护状态(例如流计算中累加wordcount)。针对这种情况,updateStateByKey()为我们提供了对一个状态变量的访问,用于键值对形式的 DStream。给定一个由(键,事件)对构成的 DStream,并传递一个指定如何根据新的事件更新每个键对应状态的函数,它可以构建出一个新的 DStream,其内部数据为(键,状态) 对。
updateStateByKey() 的结果会是一个新的DStream,其内部的RDD 序列是由每个时间区间对应的(键,状态)对组成的。
updateStateByKey 操作使得我们可以在用新信息进行更新时保持任意的状态。为使用这个功能,需要做下面两步:
- 定义状态,状态可以是一个任意的数据类型。
- 定义状态更新函数,用此函数阐明如何使用之前的状态和来自输入流的新值对状态进行更新。
使用 updateStateByKey 需要对检查点目录进行配置,会使用检查点来保存状态。
更新版的wordcount
编写代码
package ltd.cmjava.spark.streaming
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreaming05_State {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(3))
ssc.checkpoint("cp")
// 无状态数据操作,只对当前的采集周期内的数据进行处理
// 在某些场合下,需要保留数据统计结果(状态),实现数据的汇总
// 使用有状态操作时,需要设定检查点路径
val datas = ssc.socketTextStream("hadoop100", 9999)
val wordToOne = datas.map((_,1))
//val wordToCount = wordToOne.reduceByKey(_+_)
// updateStateByKey:根据key对数据的状态进行更新
// 传递的参数中含有两个值
// 第一个值表示相同的key的value数据
// 第二个值表示缓存区相同key的value数据
val ds_state = wordToOne.updateStateByKey(
( seq:Seq[Int], buff:Option[Int] ) => {
print(seq)
print(buff)
val newCount = buff.getOrElse(0) + seq.sum
Option(newCount)
}
)
ds_state.print()
ssc.start()
ssc.awaitTermination()
}
}
或者
package ltd.cmjava.spark.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreaming05_UpdateStateByKey {
def main(args: Array[String]) {
// 定义更新状态方法,参数 values 为当前批次单词频度,state 为以往批次单词频度
val updateFunc = (values: Seq[Int], state: Option[Int]) => {
val currentCount = values.foldLeft(0)(_ + _)
val previousCount = state.getOrElse(0)
Some(currentCount + previousCount)
}
val conf = new SparkConf().setMaster("local[*]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(3))
ssc.checkpoint("./ck")
// Create a DStream that will connect to hostname:port, like hadoop100:9999
val lines = ssc.socketTextStream("hadoop100", 9999)
// Split each line into words
val words = lines.flatMap(_.split(" "))
//import org.apache.spark.streaming.StreamingContext._
// not necessary since Spark 1.3
// Count each word in each batch
val pairs = words.map(word => (word, 1))
// 使用 updateStateByKey 来更新状态,统计从运行开始以来单词总的次数
val stateDstream = pairs.updateStateByKey[Int](updateFunc) stateDstream.print()
ssc.start()
ssc.awaitTermination() // Wait for the computation to terminate
//ssc.stop()
}
}
启动程序并向 9999 端口发送数据
nc -lk 9999
Hello World
Hello Scala
WindowOperations
Window Operations 可以设置窗口的大小和滑动窗口的间隔来动态的获取当前Steaming 的允许状态。所有基于窗口的操作都需要两个参数,分别为窗口时长以及滑动步长。
- 窗口时长:计算内容的时间范围;
- 滑动步长:隔多久触发一次计算。
注意: 这两者都必须为采集周期大小的整数倍。
WordCount 第三版(3 秒一个批次,窗口 12 秒,滑步 6 秒)
package ltd.cmjava.spark.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreaming06_State_Window {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(3))
val lines = ssc.socketTextStream("hadoop100", 9999)
val wordToOne = lines.map((_,1))
// 窗口的范围应该是采集周期的整数倍
// 窗口可以滑动的,但是默认情况下,一个采集周期进行滑动
// 这样的话,可能会出现重复数据的计算,为了避免这种情况,可以改变滑动的滑动(步长)
val windowDS: DStream[(String, Int)] = wordToOne.window(Seconds(12), Seconds(6))
val wordToCount = windowDS.reduceByKey(_+_)
wordToCount.print()
ssc.start()
ssc.awaitTermination()
}
}
或者
package ltd.cmjava.spark.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreaming06_State_Window1 {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(3))
ssc.checkpoint("cp")
val lines = ssc.socketTextStream("hadoop100", 9999)
val wordToOne = lines.map((_,1))
// reduceByKeyAndWindow : 当窗口范围比较大,但是滑动幅度比较小,那么可以采用增加数据和删除数据的方式
// 无需重复计算,提升性能。
val windowDS: DStream[(String, Int)] =
wordToOne.reduceByKeyAndWindow(
(x:Int, y:Int) => { x + y},
(x:Int, y:Int) => {x - y},
Seconds(12), Seconds(6))
windowDS.print()
ssc.start()
ssc.awaitTermination()
}
}
关于Window 的操作还有如下方法:
- window(windowLength, slideInterval): 基于对源DStream 窗化的批次进行计算返回一个新的Dstream;
- countByWindow(windowLength, slideInterval): 返回一个滑动窗口计数流中的元素个数。countByWindow()和countByValueAndWindow()作为对数据进行计数操作的简写。 countByWindow()返回一个表示每个窗口中元素个数的 DStream,而 countByValueAndWindow()返回的 DStream 则包含窗口中每个值的个数。
val ipDStream = accessLogsDStream.map{entry => entry.getIpAddress()} val ipAddressRequestCount = ipDStream.countByValueAndWindow(Seconds(30), Seconds(10))
val requestCount = accessLogsDStream.countByWindow(Seconds(30), Seconds(10))
- reduceByWindow(func, windowLength, slideInterval): 通过使用自定义函数整合滑动区间流元素来创建一个新的单元素流;
- reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks]): 当在一个(K,V)对的DStream 上调用此函数,会返回一个新(K,V)对的 DStream,此处通过对滑动窗口中批次数据使用 reduce 函数来整合每个 key 的 value 值。
- reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks]): 这个函数是上述函数的变化版本,每个窗口的 reduce 值都是通过用前一个窗的 reduce 值来递增计算。通过 reduce 进入到滑动窗口数据并”反向 reduce”离开窗口的旧数据来实现这个操作。一个例子是随着窗口滑动对keys 的“加”“减”计数。通过前边介绍可以想到,这个函数只适用于”可逆的 reduce 函数”,也就是这些 reduce 函数有相应的”反 reduce”函数(以参数 invFunc 形式传入)。如前述函数,reduce 任务的数量通过可选参数来配置。
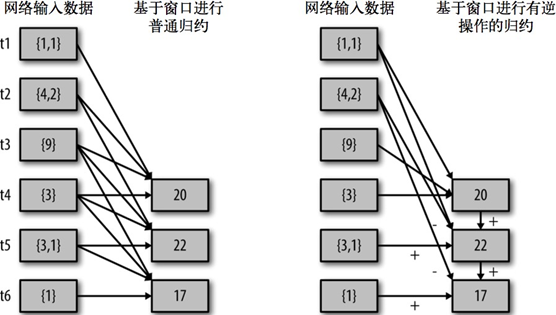
val ipDStream = accessLogsDStream.map(logEntry => (logEntry.getIpAddress(), 1))
val ipCountDStream = ipDStream.reduceByKeyAndWindow(
{(x, y) => x + y},
{(x, y) => x - y},
Seconds(30),
Seconds(10))
//加上新进入窗口的批次中的元素 //移除离开窗口的老批次中的元素 //窗口时长// 滑动步长
DStream 输出
输出操作指定了对流数据经转化操作得到的数据所要执行的操作(例如把结果推入外部数据库或输出到屏幕上)。与RDD 中的惰性求值类似,如果一个 DStream 及其派生出的DStream 都没有被执行输出操作,那么这些DStream 就都不会被求值。如果 StreamingContext 中没有设定输出操作,整个context 就都不会启动。
案例代码
package ltd.cmjava.spark.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreaming07_Output {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(3))
ssc.checkpoint("cp")
val lines = ssc.socketTextStream("hadoop100", 9999)
val wordToOne = lines.map((_,1))
val windowDS: DStream[(String, Int)] =
wordToOne.reduceByKeyAndWindow(
(x:Int, y:Int) => { x + y},
(x:Int, y:Int) => {x - y},
Seconds(9), Seconds(3))
// SparkStreaming如何没有输出操作,那么会提示错误
//windowDS.print()
ssc.start()
ssc.awaitTermination()
}
}
package ltd.cmjava.spark.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreaming07_Output1 {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(3))
ssc.checkpoint("cp")
val lines = ssc.socketTextStream("hadoop100", 9999)
val wordToOne = lines.map((_,1))
val windowDS: DStream[(String, Int)] =
wordToOne.reduceByKeyAndWindow(
(x:Int, y:Int) => { x + y},
(x:Int, y:Int) => {x - y},
Seconds(9), Seconds(3))
// foreachRDD不会出现时间戳
windowDS.foreachRDD(
rdd => {
}
)
ssc.start()
ssc.awaitTermination()
}
}
常见API
- print():在运行流程序的驱动结点上打印DStream 中每一批次数据的最开始 10 个元素。这用于开发和调试。在 Python API 中,同样的操作叫 print()。
- saveAsTextFiles(prefix, [suffix]):以 text 文件形式存储这个 DStream 的内容。每一批次的存储文件名基于参数中的 prefix 和 suffix。”prefix-Time_IN_MS[.suffix]”。
- saveAsObjectFiles(prefix, [suffix]):以 Java 对象序列化的方式将 Stream 中的数据保存为 SequenceFiles . 每一批次的存储文件名基于参数中的为"prefix-TIME_IN_MS[.suffix]". Python中目前不可用。
- saveAsHadoopFiles(prefix, [suffix]):将 Stream 中的数据保存为 Hadoop files. 每一批次的存储文件名基于参数中的为"prefix-TIME_IN_MS[.suffix]"。Python API 中目前不可用。
- foreachRDD(func):这是最通用的输出操作,即将函数 func 用于产生于 stream 的每一个 RDD。其中参数传入的函数 func 应该实现将每一个RDD 中数据推送到外部系统,如将 RDD 存入文件或者通过网络将其写入数据库。
通用的输出操作foreachRDD(),它用来对DStream 中的 RDD 运行任意计算。这和 transform()有些类似,都可以让我们访问任意RDD。在 foreachRDD()中,可以重用我们在 Spark 中实现的所有行动操作。比如,常见的用例之一是把数据写到诸如 MySQL 的外部数据库中。
注意:
- 连接不能写在 driver 层面(序列化)
- 如果写在 foreach 则每个 RDD 中的每一条数据都创建,得不偿失;
- 增加 foreachPartition,在分区创建(获取)。
优雅关闭
流式任务需要 7*24 小时执行,但是有时涉及到升级代码需要主动停止程序,但是分布式程序,没办法做到一个个进程去杀死,所有配置优雅的关闭就显得至关重要了。
使用外部文件系统来控制内部程序关闭。
package ltd.cmjava.spark.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext, StreamingContextState}
import scala.util.control.Breaks
import scala.util.control.Breaks.break
object SparkStreaming08_Close {
def main(args: Array[String]): Unit = {
/*
线程的关闭:
val thread = new Thread()
thread.start()
thread.stop(); // 强制关闭
*/
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(3))
val lines = ssc.socketTextStream("hadoop100", 9999)
val wordToOne = lines.map((_, 1))
wordToOne.print()
ssc.start()
// 如果想要关闭采集器,那么需要创建新的线程
// 而且需要在第三方程序中增加关闭状态
new Thread(
new Runnable {
override def run(): Unit = {
// 优雅地关闭
// 计算节点不在接收新的数据,而是将现有的数据处理完毕,然后关闭
// Mysql : Table(stopSpark) => Row => data
// Redis : Data(K-V)
// ZK : /stopSpark
// HDFS : /stopSpark
Thread.sleep(5000)
var loop = new Breaks;
loop.breakable {
while (true) {
// 获取SparkStreaming状态
val state: StreamingContextState = ssc.getState()
if (state == StreamingContextState.ACTIVE) {
ssc.stop(true, true)
println("关闭StreamingContext")
loop.break()
}
Thread.sleep(5000)
}
}
// Thread.sleep(5000)
// val state: StreamingContextState = ssc.getState()
// if (state == StreamingContextState.ACTIVE) {
// ssc.stop(true, true)
// }
System.exit(0)
}
}
).start()
ssc.awaitTermination() // block 阻塞main线程
}
}
数据的恢复
package ltd.cmjava.spark.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext, StreamingContextState}
object SparkStreaming09_Resume {
def main(args: Array[String]): Unit = {
// 从检查点恢复StreamingContext
val ssc = StreamingContext.getActiveOrCreate("cp", ()=>{
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(3))
val lines = ssc.socketTextStream("hadoop100", 9999)
val wordToOne = lines.map((_,1))
wordToOne.print()
ssc
})
ssc.checkpoint("cp")
ssc.start()
ssc.awaitTermination() // block 阻塞main线程
}
}
评论区